
안녕하세요! GDSC Sungshin 교육팀 김도은입니다!
1월 정기세션에서 교육팀은 ' Database '라는 주제로 교육을 진행했습니다.
Database basic, Transaction, Database Lock 순으로 진행했습니다.
먼저 데이터베이스 원칙에 대해 알려드리겠습니다.
데이터베이스에는 데이터가 전송, 저장, 처리되는 과정에서 변경되거나 손상되지 않는 무결성, 인증/인가되지 않는 사용자로부터 데이터를 보호하는 안정성, 데이터 양, 사용자의 양에 따라 유연하게 scale out, scale up 대처를 할 수 있는 확장성이 있습니다.
이제 데이터베이스 종류에 대해 설명해드리겠습니다.
데이터베이스는 크게 관계형 데이터베이스와 비관계형 데이터베이스로 나눌 수 있습니다.
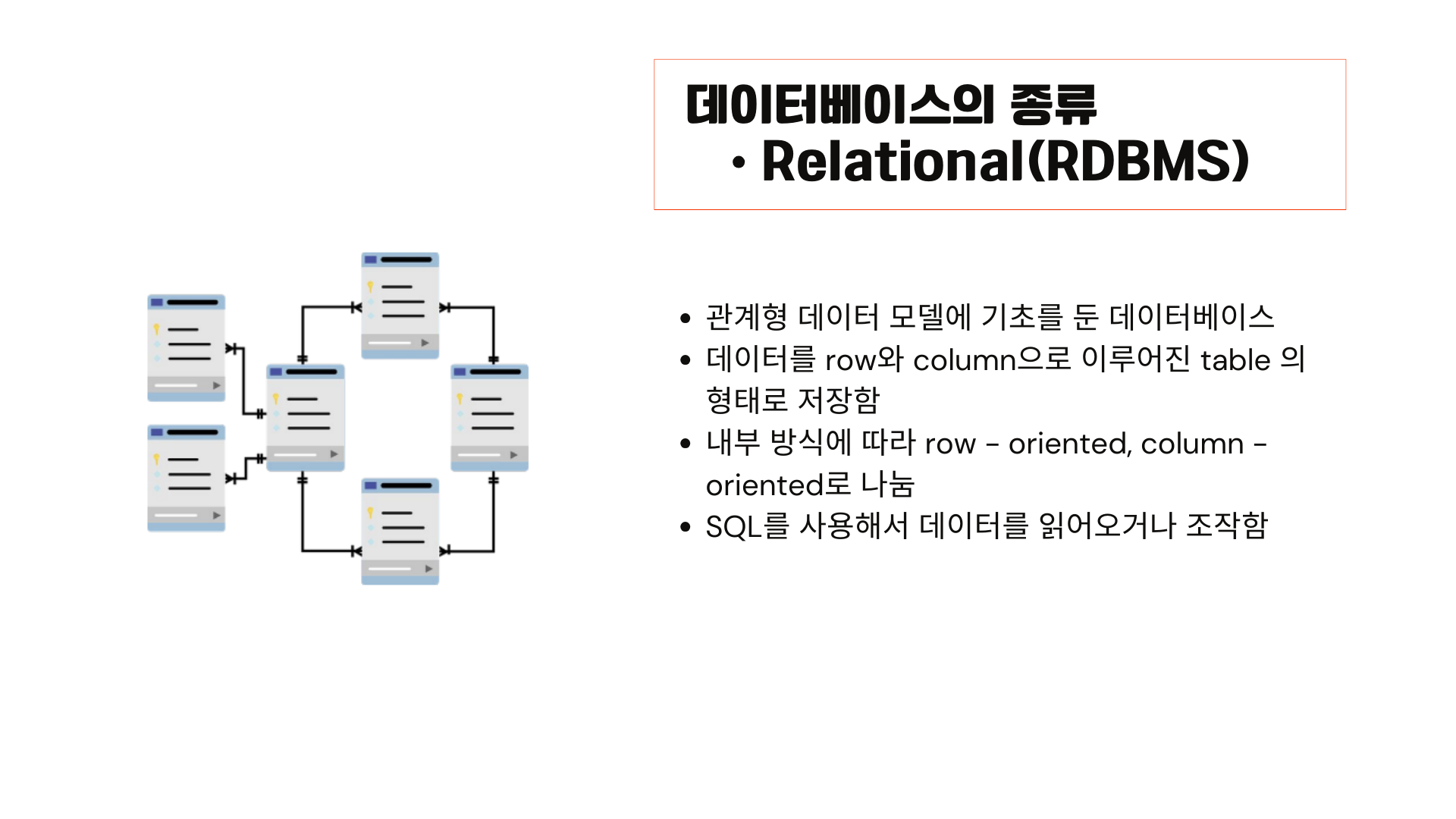
RDBMS는 관계형 데이터 모델에 기초를 둔 데이터베이스 입니다. 데이터를 row와 column으로 이루어진 table의 형태로 저장합니다.
sql를 사용해서 데이터를 읽거나 조작합니다.
저장하는 내부 방식에 따라 row-oriented와 column-oriented로 나눌 수 있습니다.

row-oriented는 각 데이터를 레코드 단위로 기록되며, 메모리 상 레코드끼리 수평적으로 저장합니다.
데이터의 끝에 행을 추가하기만 하면 되기 떄문에 저장속도가 빠르고 행 단위 데이터를 불러오는 속도가 빠르다는 장점이 있습니다.
반면에 데이터 간의 집합을 만드는 경우, 속도 저하 현상이 발생하고, 불필요한 연산 시간을 초래하며 간편한 입력에 비해 출력하는 과정이 필요 이상의 메모리 소모를 유발한다는 단점이 있습니다. 대표적인 예로는 mysql이 있습니다.

column-oriented는 각 데이터를 필드 단위로 기록되며, 메모리 상 필드끼리 수평적으로 저장합니다.
데이터 쿼리를 할 때 성능이 더 좋은 경우가 있습니다. 데이터 집합을 만드는 경우 추가 메모리 소모 없이 필요한 결과를 출력할 수 있으며 이에 따라 성능이 크게 향상한다는 장점이 있습니다. 반면에 데이터 저장 시에 중간 저장이 필요하므로 효율이 떨어지고, 행 단위 데이터를 불러오기 위해 각 disk별로 조회하기 때문에 효율이 떨어진다는 단점이 있습니다.
대표적인 예시로는 bigquery가 있습니다.

이제 비관계형 데이터베이스인 NoSQL에 대해 설명해드리겠습니다.
NoSQL에는 key-value라는 종류가 있습니다.
key-value가 짝으로 이루어져 데이터를 저장합니다. key값은 독특해야 하고 중복이 불가능 합지만 value값은 중복되는 내용이 들어가도 됩니다. 대표적인 예로는 redis와 dynamoDB가 있습니다.
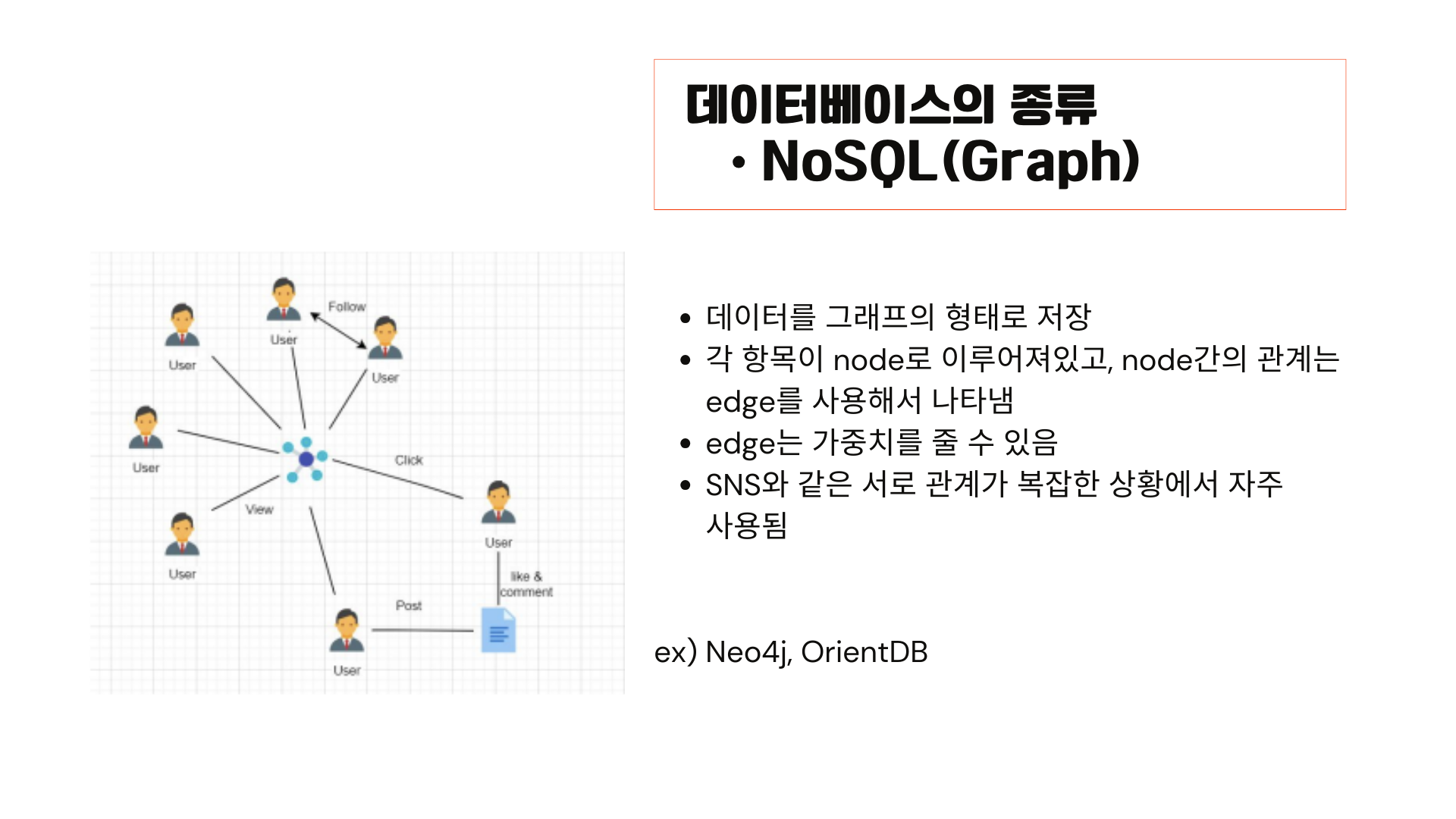
Nosql의 또 다른 종류로는 그래프가 있습니다.
각 항목이 node로 이루어져 있고, node 간의 관계는 edge를 사용해서 나타냅니다. edge에 가중치를 줄 수도 있습니다. sns와 같은 서로 관계가 복잡한 상황에서 자주 사용됩니다. 대표적인 예로는 neo4 j, orientdb가 있습니다.

nosql의 마지막 종류로 document database가 있습니다. row, column과 같은 구조는 없고 자유로운 형태로 데이터를 저장합니다. 일반적으로 json이나 xml의 형태로 저장합니다. 데이터베이스 별로 데이터를 조작할 수 있는 언어가 따로 있습니다. 대표적인 예로는 mongodb가 있습니다.

RDBMS와 NoSQL의 차이점에 대해 정리하겠습니다.
먼저 RDBMS의 데이터 모델링은 스키마에 맞춰서 관리하기 때문에 데이터 정합성을 보장할 수 있습니다. 또한 관계를 맺고 있는 데이터가 자주 변경되는 경우 RDBMS를 사용합니다.
확장성은 scale up을 사용하고 쿼리 언어는 sql을 사용합니다. 유연성은 상대적으로 떨어집니다.
NoSQL의 데이터 모델링은 자유롭게 데이터를 관리할 수 있고 데이터 구조를 정확히 알 수 없고, 데이터가 변경/확장이 될 가능성이 있는 경우 nosql을 사용합니다. 확장성은 scale out을 사용하고 쿼리 언어는 DB마다 문법이 다릅니다. 유연성은 매우 유연합니다.

다음으로 트랜잭션에 대해 예제를 통해 설명해 드리겠습니다.
j가 h에게 20만 원을 이체한다면
db상에서 각자의 계좌에서는
어떤 변경이 발생할까요?
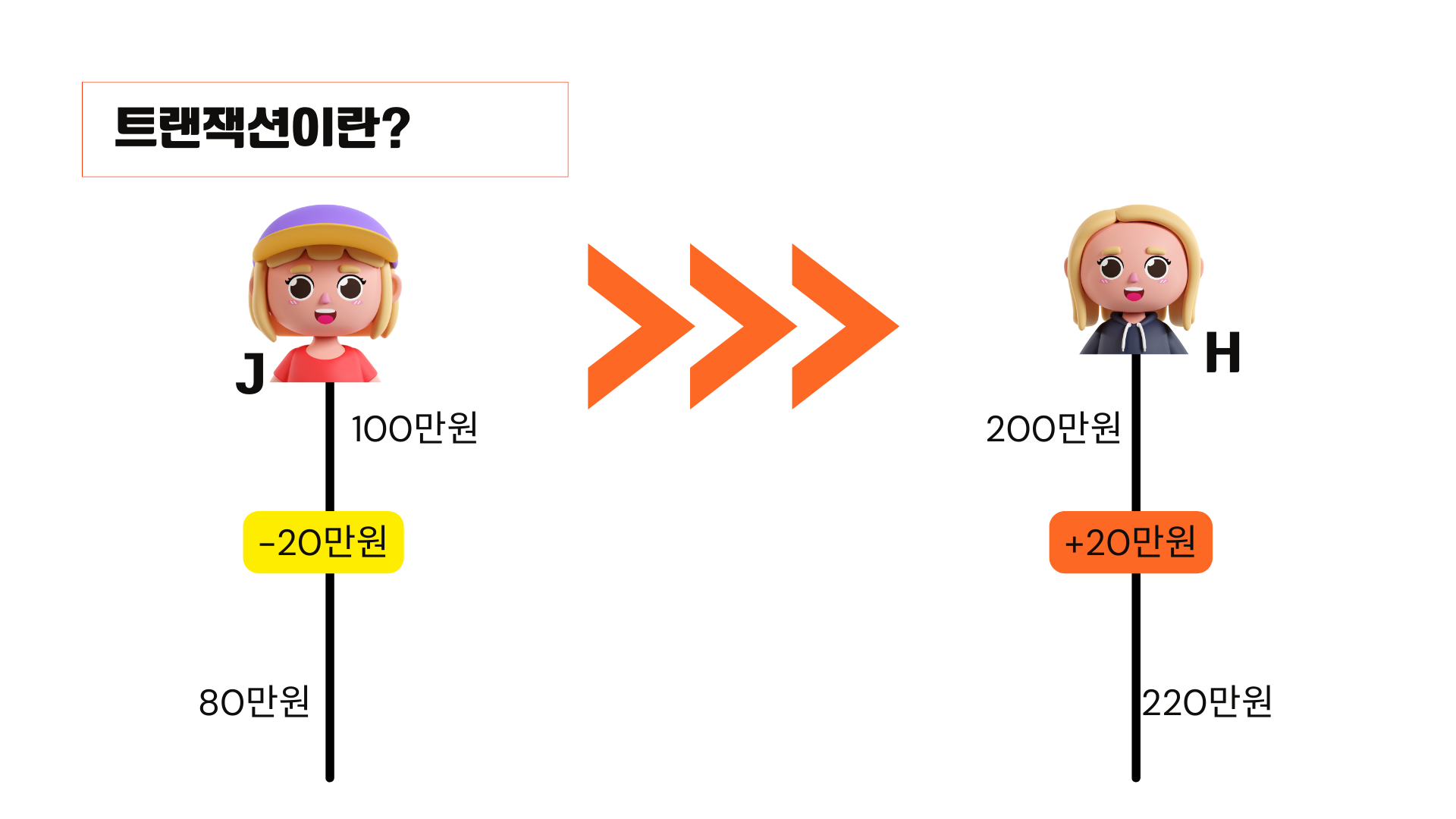
j는 계좌에 100만 원이 있고 h는 계좌에 200만 원이 있습니다.
j가 H에게 이체를 하려고 하는 겁니다. j의 계좌에서 20만 원을 빼서 80만 원이 남게 됩니다.
이제는 H계좌에 20을 넣어야겠죠 h계좌는 최종적으로는 220만 원이 될 겁니다.
노란색과 주황색 부분을 sql 문으로 표현하게 되면,
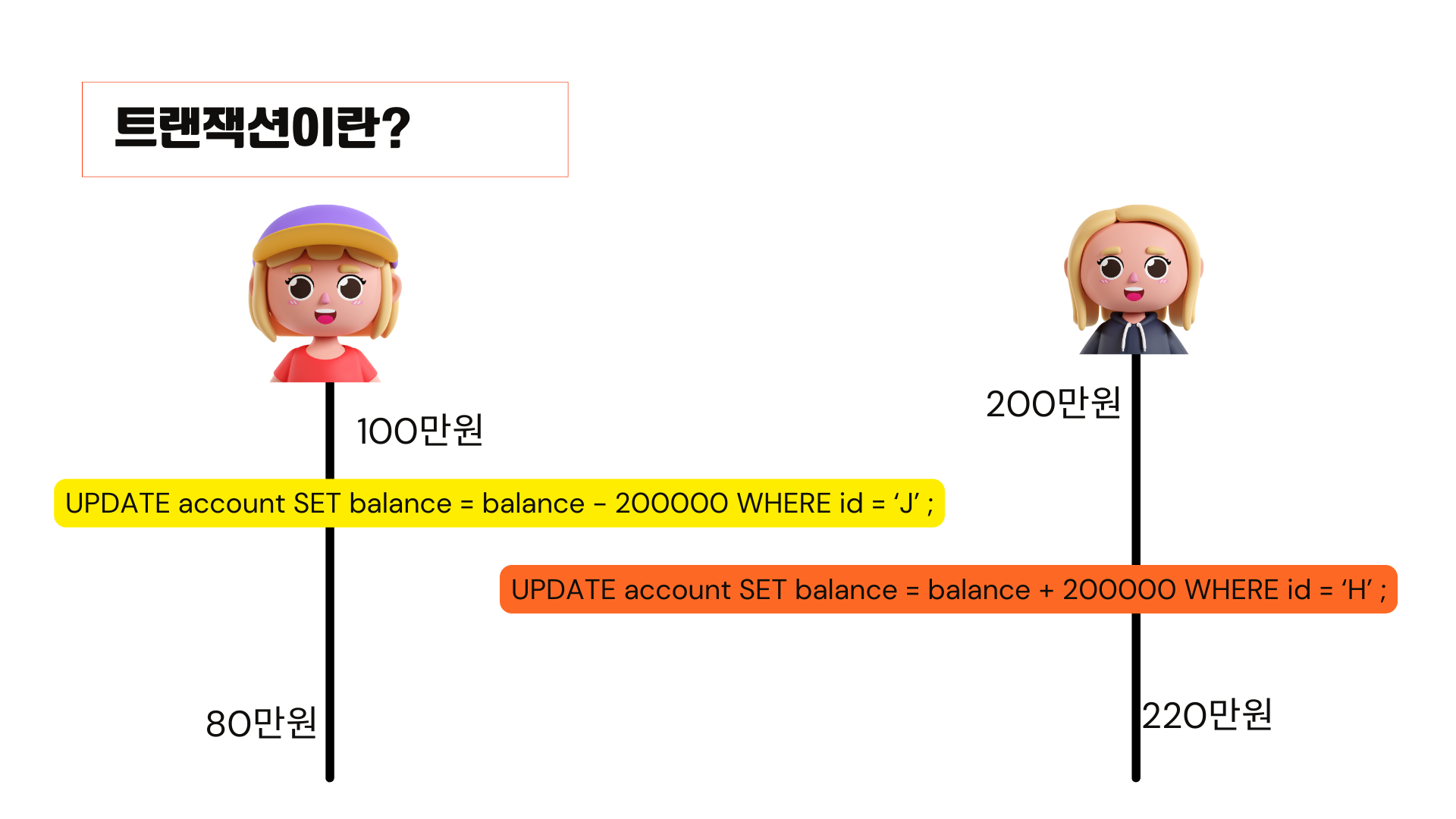
account라는 테이블이 있고 j에 대해서 이 밸런스, 잔액이라는 의미죠. 여기서 20만 원을 빼줘서 새로운 밸런스 값으로 업데이트해주는 겁니다. 옆에도 마찬가지로 h에 대해서 같은 어카운트 테이블에 대해서 밸런스 20만원을 더해서 새로운 밸런스로 업데이트 해주는 겁니다.
여기서 어떤 게 중요하냐면, 이 둘 다 성공을 해야만 "이체"라는 작업이 성공하게 되는 겁니다.
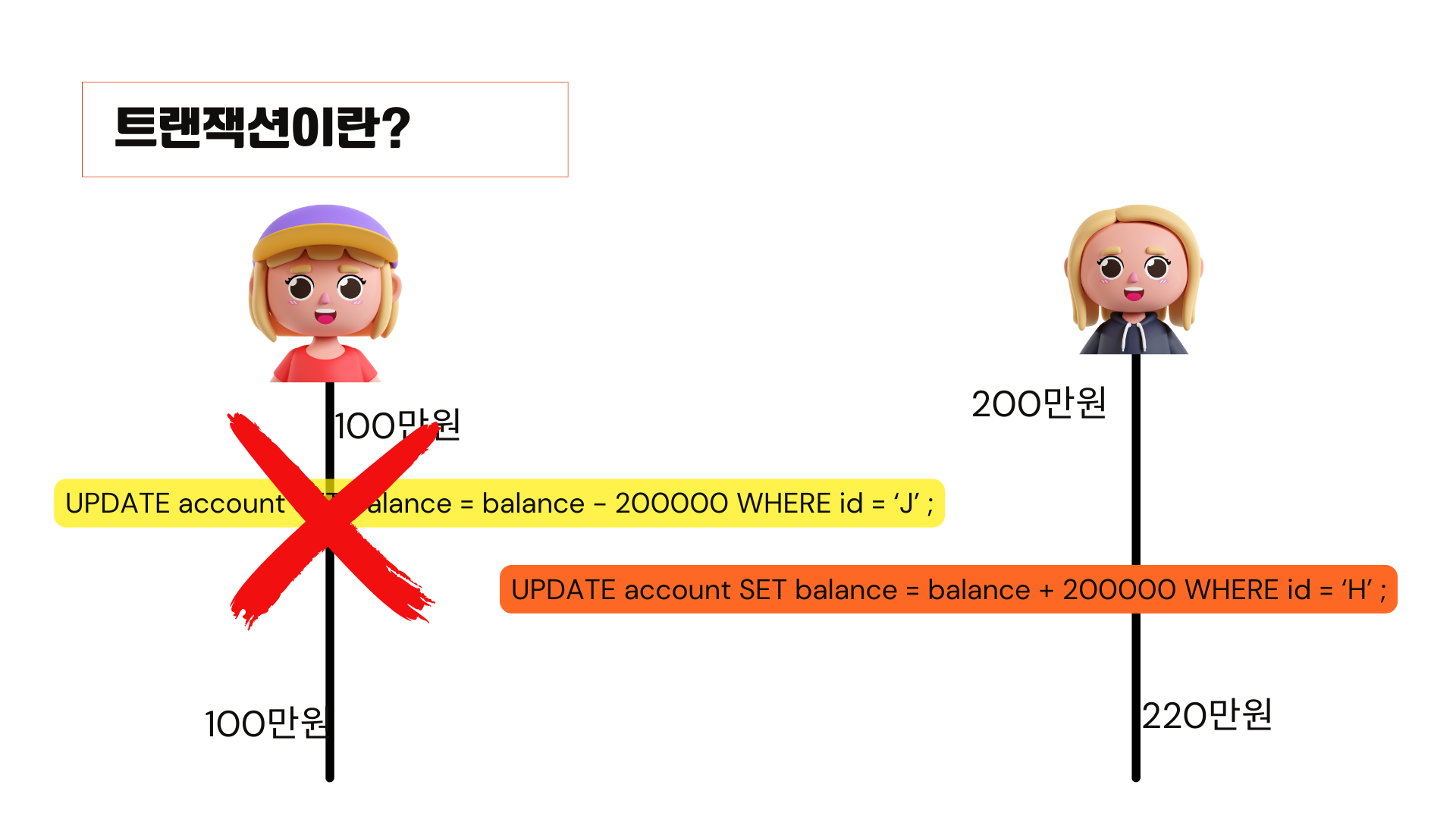
만약에 주황색은 성공을 하고 노란색은 실패를 하게 되면 j의 계좌에는 100만 원이 남아있는데 h의 계좌는 220만 원이 된겁니다. 존재하지 않은 20만원이 생긴 거죠.
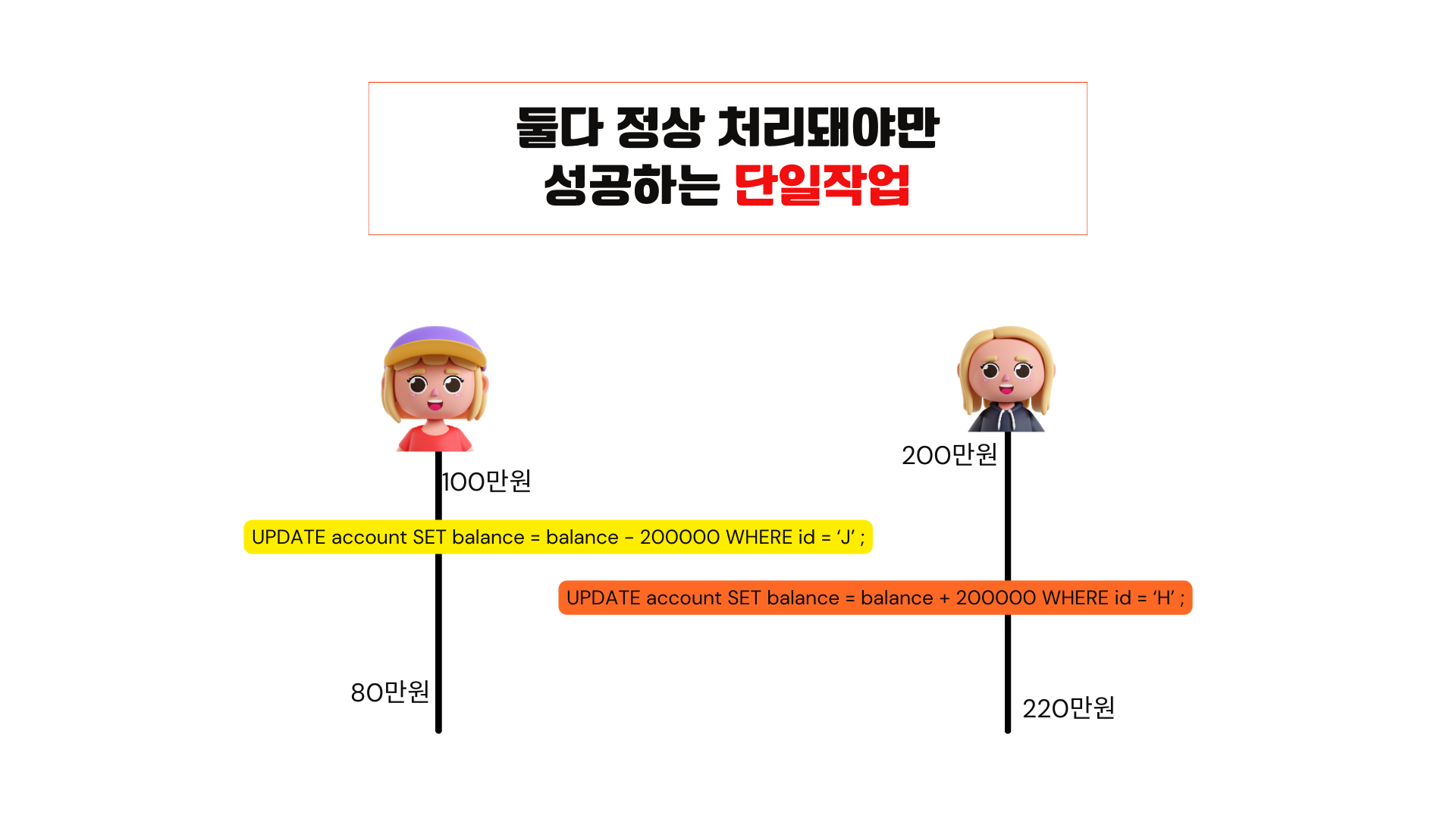
지금 두 개의 업데이트 문을 사용해서 이체라는 작업을 진행했는데. 하나만 성공해서는 정상적으로 처리가 안 되는 둘 다 정상처리돼야만 성공하는 단일작업입니다.
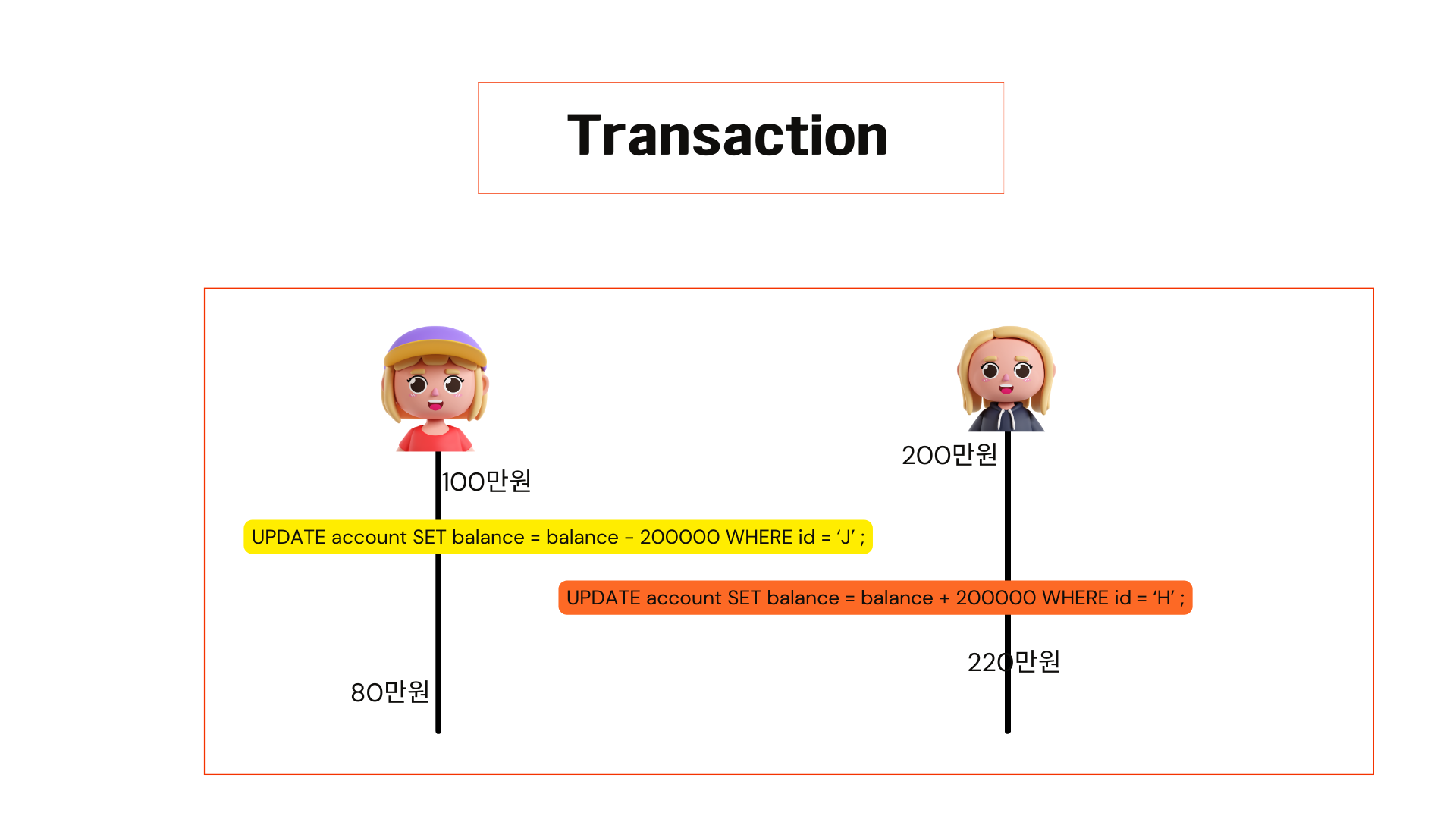
이렇게 sql문이 모두 성공을 해야만 의미가 있는 이런 작업을 데이터베이스에서 트랜잭션이라고 합니다.

트랜잭션의 특징에 대해 살펴보겠습니다. 단일한 논리적인 작업 단위이며 논리적인 이유로 여러 sql문들을 단일 작업으로 묶어서 나눠질 수 없게 만든 것이고,트랜잭션 내부의 sql문들 중에 일부만 성공해서 db에 반영되는 일은 일어나지 않습니다. (모두 성공해야만 반영됩니다.)

j가 h에게 20만 원 이체한 것을 트랜잭션으로 구현해 보겠습니다. 먼저 start transaction 명령어를 실행합니다. 이건 트랜잭션을 시작한다는 걸 알려주는 명령어입니다.
그리고 업데이트 문을 수행하고 이 두 개가 성공적으로 수행하면, 커밋을 해줍니다. 커밋은 무엇이냐면 지금까지 작업한 내용을 DB에 영구적으로 저장하라 또 트랜잭션을 종료한다는 의미입니다.

다음으로 트랜잭션의 핵심 acid에 대해서 살표 보겠습니다. 각글자의 첫 글자를 딴 것입니다. 이는 트랜잭션이 어떤 속성을 지녀야 하는지를 나타내는 속성입니다. 하나씩 살펴보겠습니다.
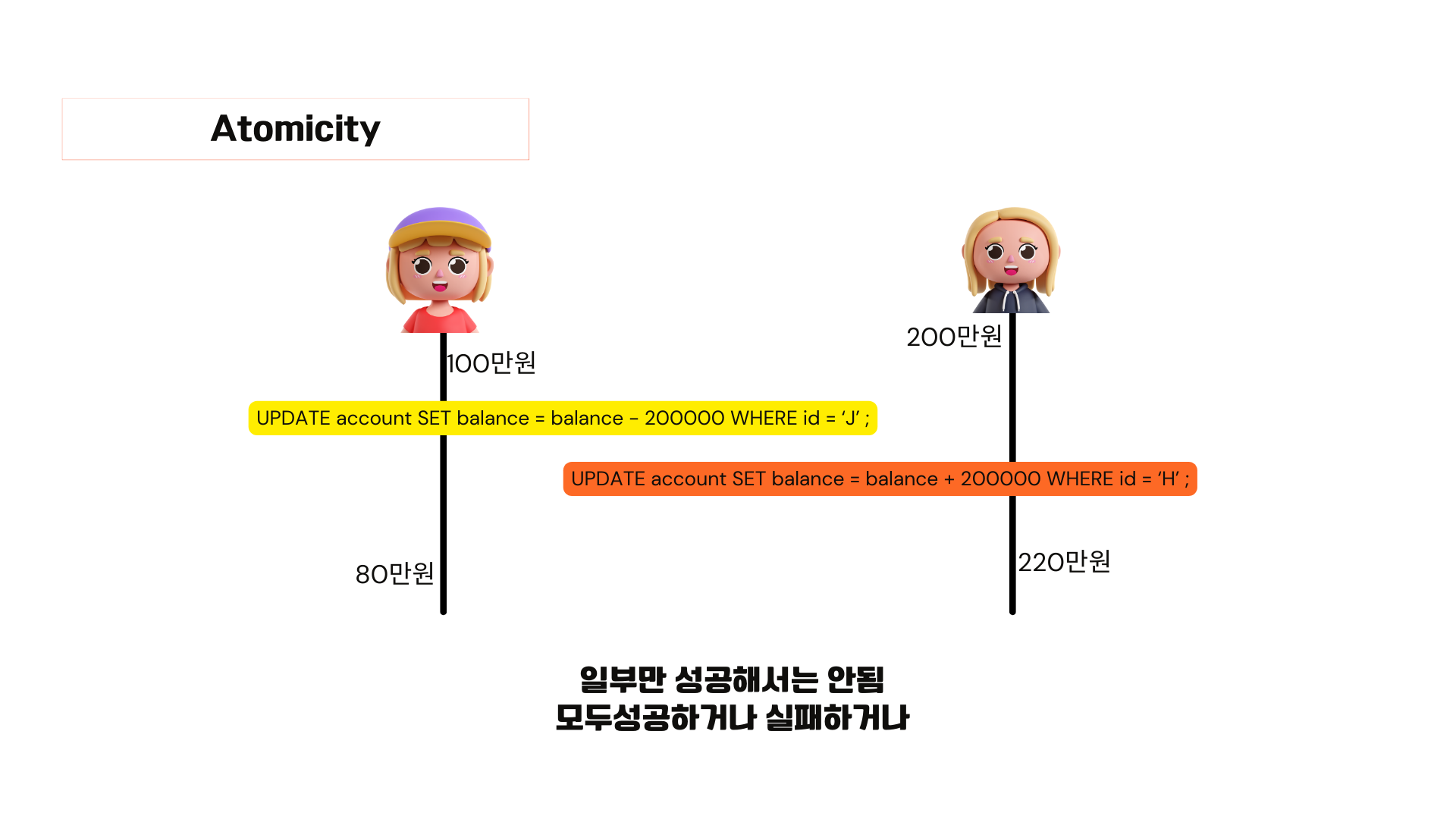
아까 살펴봤던 예제입니다. 이는 일부만 성공해서는 안됩니다.
모두성공하거나 실패해야 합니다. 이런 트랜잭션의 특징을 Atomicity라고 합니다.

All or Nothing이라는 개념인데요. 모두성공하거나 아예 아무 일도 일어나지 않아야합니다. 왜냐면 트랜잭션은 논리적으로 쪼개질 수 없는 작업 단위이기 때문에 내부의 sql문들이 모두 성공해야하는 겁니다. 그런데 만약 중간에 sql 문이 실패하면 지금까지의 작업을 모두 취소하여 아무일도 없었던 것처럼 rollback 해야 합니다. 커밋 실행 시 db에 영구적으로 저장하는 것은 dbms가 담당하는 부분이고, rollback실행 시 이전 상태로 되돌리는 것도 dbms가 담당하는 부분입니다. 개발자는 언제 커밋하거나 롤백할지를 챙겨야 합니다.
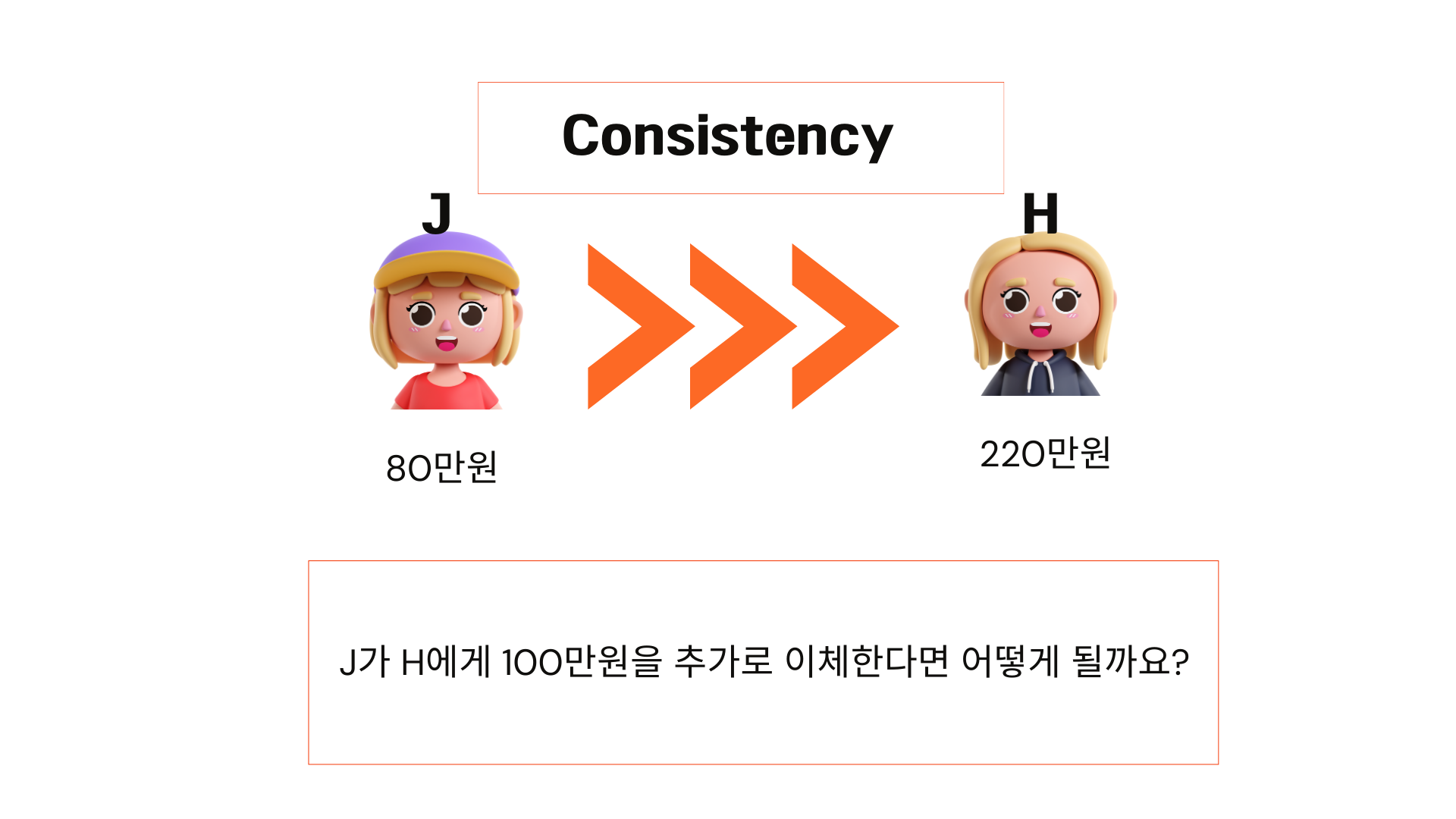
다음으로 consistency 우리말로 일관성에 대한 소개입니다. J가 H에게 100만 원을 추가로 이체한다면 어떻게 될까요?
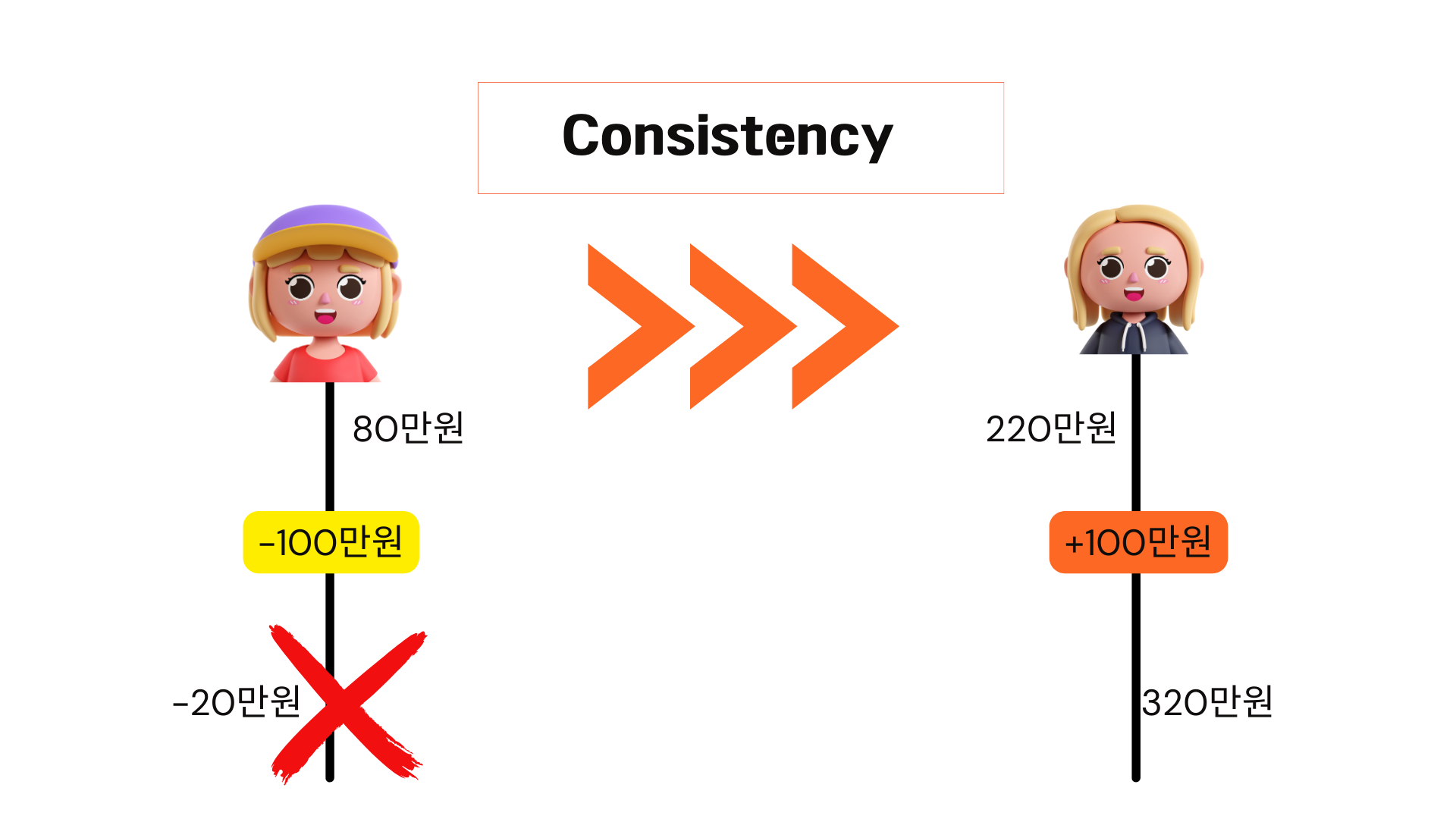
앞에서 했던 것들을 비슷하게 수행하면 됩니다. j의 계좌에서 100만 원을 빼주고 h의 계좌에서 100을 더해주면 됩니다. 결과적으로 j는 -20이 되고 h는 320만 원이 됩니다. 근데 문제가 하나 있습니다. 우리가 테이블을 생성할 때 계좌잔액이 음수가 될 수없습니다. 즉 0보다 커야 한다는 제약사항을 넣었다고 할 때, 이 왼쪽 업데이트 문은 실패하게 됩니다. 일관성을 깨뜨리기 때문에 수행할 수 없다고 에러가 뜨고 왼쪽 업데이트문은 실행시키지 않습니다. 이런 상태에서 이 트랜잭션을 수행하는 것은 아무 의미가 없기 때문에 롤백을 해줘야 하는 겁니다. 이렇게 데이터베이스에 일관성을 유지시켜 주는 것이 트랜잭션의 consistency가 의미하는 것입니다.
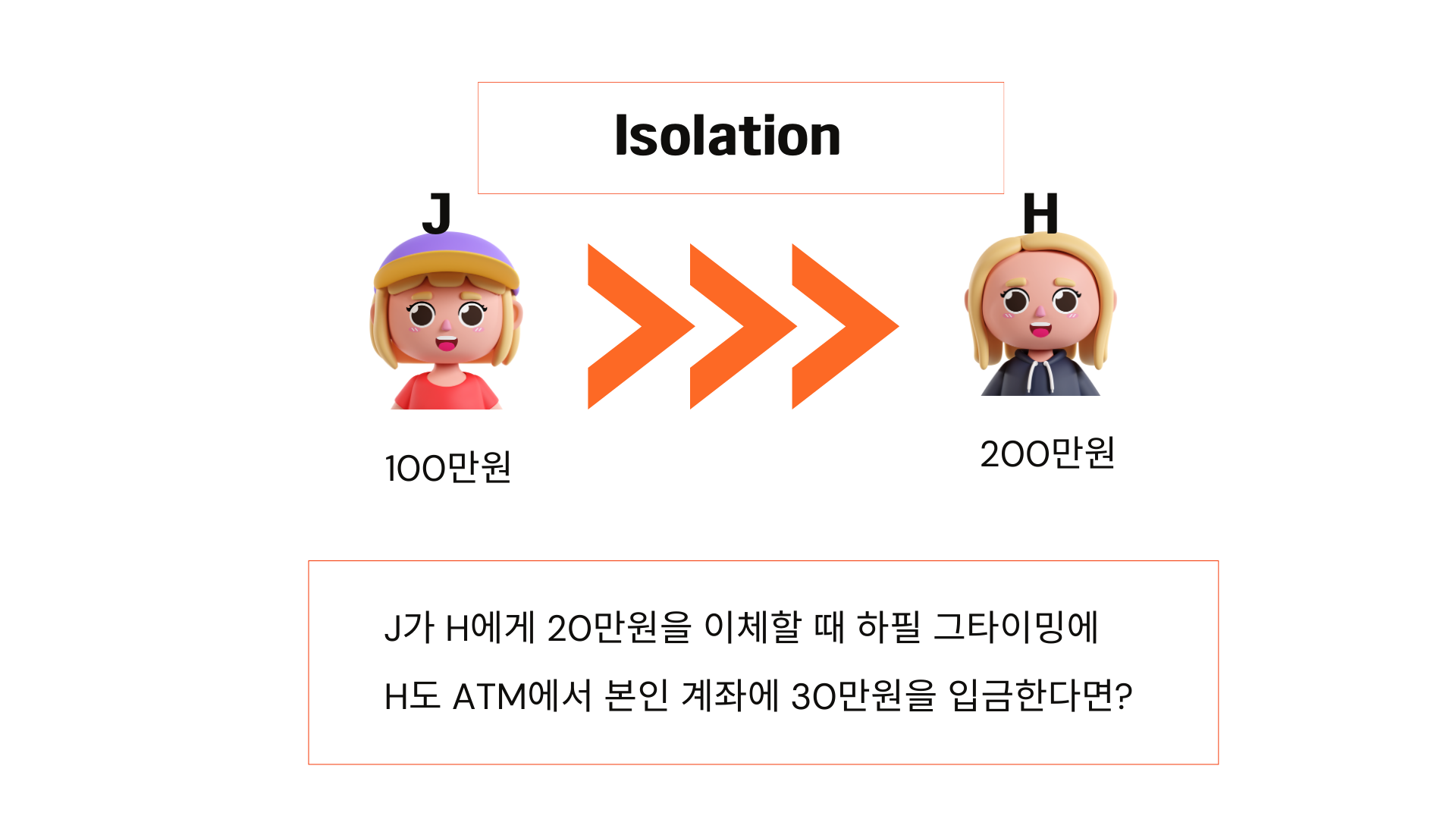
다음으로 isolation입니다. J가 H에게 20만 원을 이체할 때 하필 그 타이밍에
H도 ATM에서 본인 계좌에 30만 원을 입금한다면?
어떻게 될까요?
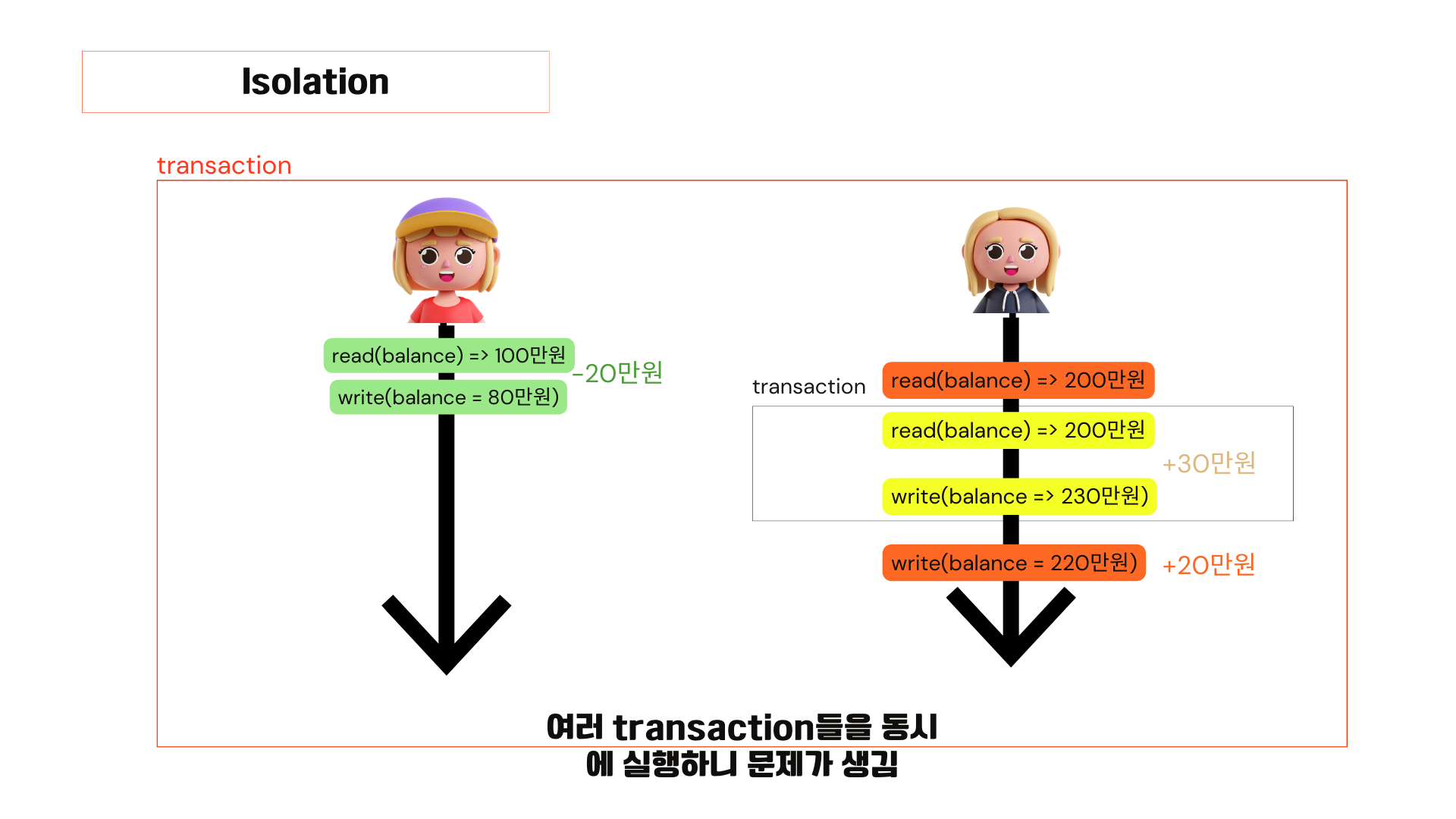
아까 본 예제인데 더 자세히 볼게요. 자세히 보면 j의 계좌에 얼마가 있는지 잔액을 확인해야 하니까 100만 원이 남아있다는 것을 확인했습니다. read100에서 20을 빼주면 80만 원이 되고 80만 원을 write 해줍니다. 그러고 h의 계좌에 넣어줘야 하니까 h계좌의 잔액을 확인합니다. 200만 원이 있다는 것을 확인하고 200에 20을 더해서 220만 원을 h의 계좌에 써주면 되는 건데, 이 타이밍에 h가 atm에서 30만 원을 입금하는 트랜잭션이 발생합니다. 동작 방식을 살펴보면, 30만 원을 입금해줘야하니까 일단 h계좌에 얼마가 있는지 잔액을 확인해줘야하니까 read를 했는데 h의 계좌가 업데이트가 되지 않은 상태기 때문에 기존의 잔액 200만원을 읽어오고 30만원을 더해줘서 230만 원을 write해주는 것입니다. 그리고 이 노란색 트랜잭션은 커밋이 되고 끝이 납니다.
이어서 원래 진행되고 있던 트랜잭션이 수행됩니다. 이 트랜잭션은 30만 원이 추가가 됐다는 사실을 모릅니다. 왜냐면 이 노란색 트랜잭션이 수행되기 전에 이미 200만 원이라는 것을 읽어왔기 때문입니다. 이 상태에서 20만 원을 더해서 220만 원을 write 해주는 겁니다. 그리고 이 트랜잭션은 끝이 납니다. 결과적으로 가운데 있는 30만 원은 사라지게 되는 이상한 동작이 됩니다. 이처럼 여러 트랜잭션들이 동시에 일어나면 문제가 생깁니다. 이런 문제가 발생하지 않아야겠죠. 그래서 트랜잭션의 또 다른 중요한 속성이 이 아이솔레이션입니다.
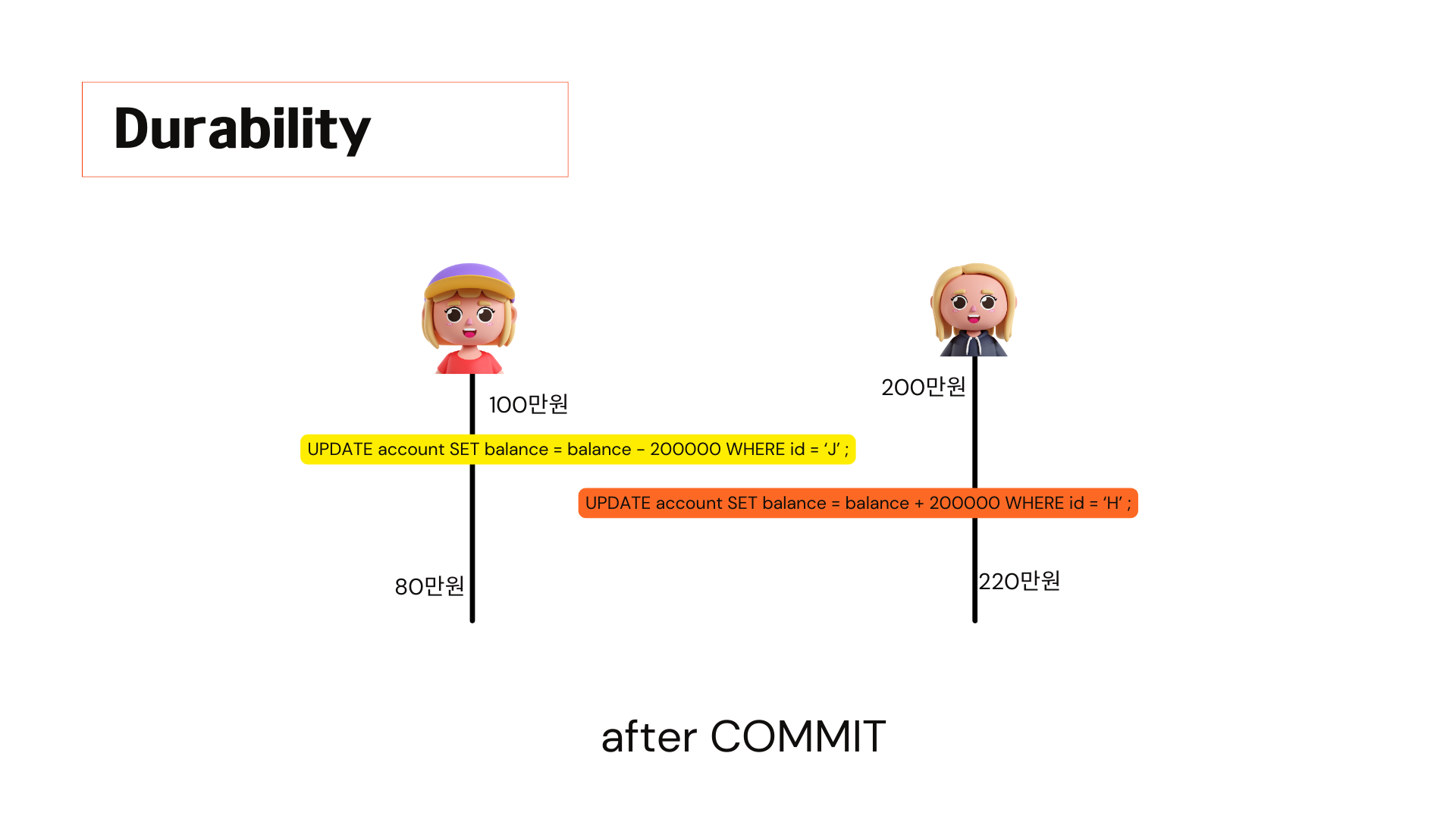
끝으로 Durability에 대해 살펴보겠습니다. 커밋이 된 트랜잭션은 db에 영구적으로 저장됩니다.

Durability는 commit 된 transaction은 DB에 영구적으로 저장된다는 의미입니다. 여기서 영구적이것은 DB시스템에 문제가 생겨도 commit된 transaction은 그대로 DB에 남아있는다는 의미입니다. DB시스템에 문제가 발생했다고 해서 커밋된 트랜잭션이 다시 롤백되거나 내용이 사라지거나 하지 않는다는 것을 의미합니다. 그리고 기본적으로 transaction의 durability는 DBMS가 보장합니다. 그래서 개발자가 이 부분을 따로 건들지 않아도 dbms가 알아서 처리한다고 생각해도 무리가 없을 것 같습니다.
끝으로 트랜잭션을 어떻게 정의해서 쓸지는 개발자가 정하는 것입니다. 구현하려는 기능과 ACID 속성을 이해해야 트랜잭션을 잘 정의할 수 있습니다. DBMS가 알아서 모든 것을 해주는 것이 아니기 때문에 ACID와 관련해서 개발자가 챙겨야 하는 부분들이 많다는 말을 끝으로 다음으로 넘어가겠습니다.

다음은 데이터 베이스 락에 대해 설명하겠습니다. 데이터베이스 락은 단어 그대로 잠금입니다. 데이터 베이스는 여러 사용자들이 같은 데이터를 동시에 접근하는 상황에서 세션이 트랜잭션을 시작하고 데이터를 수정하는 동안에는 커밋이나 롤백 전까지 다른 세션에서 해당 데이터를 수정할 수 없게 막는 역할입니다. 하나의 데이터를 동시에 여러 명이 조작할 수 없도록 하여 동시성을 보장합니다.
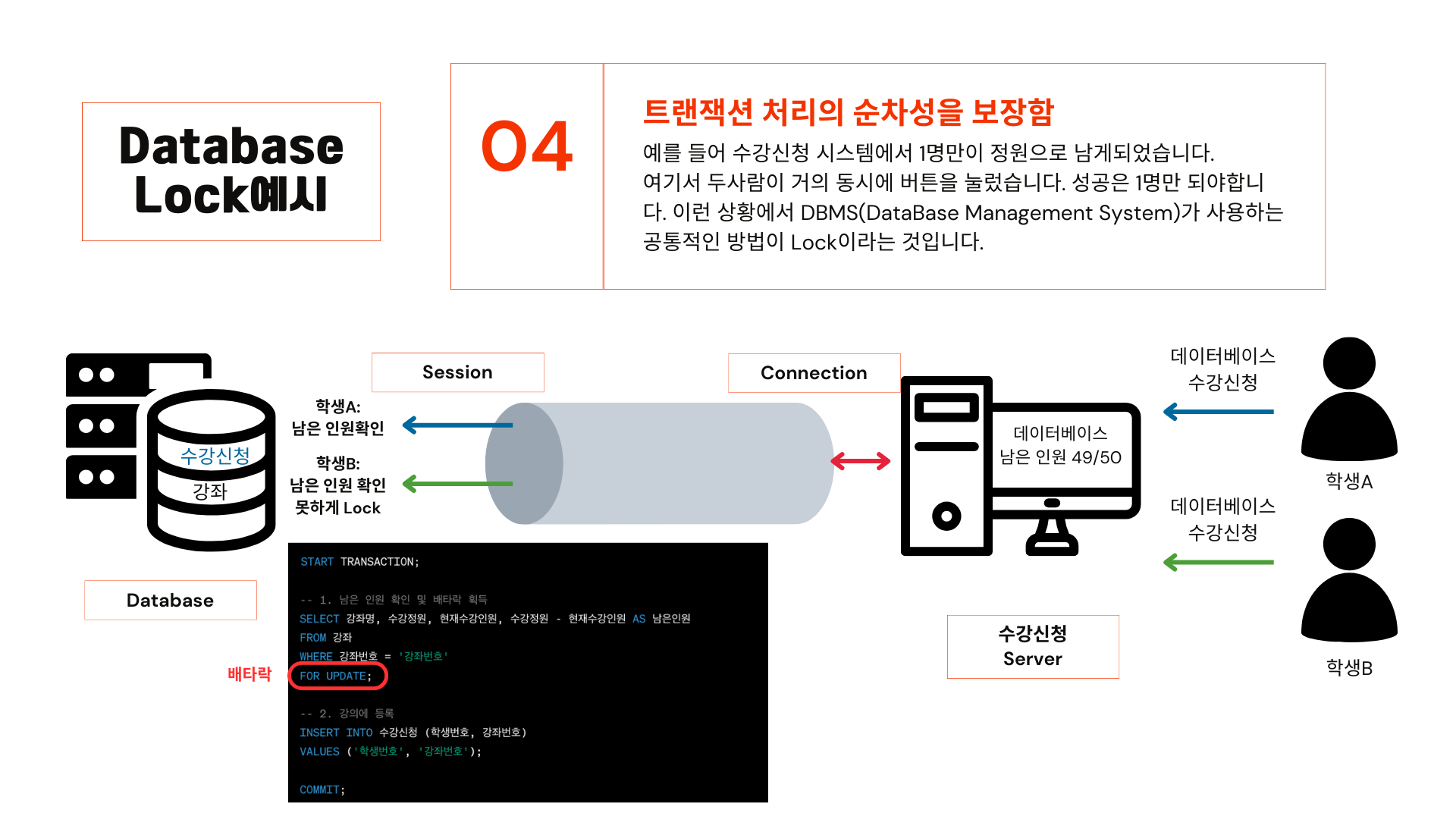
이해가 안 될 수도 있으니 데이터베이스락을 사용하는 수강신청 예제를 통해 설명해 보겠습니다. 수강신청 시스템에서 1명만이 정원으로 남게 되었습니다. 여기서 두 사람이 거의 동시에 버튼을 눌렀습니다. 성공은 1명만 되어야 합니다. 이런 상황에서 DBMS가 사용하는 방법이 Lock이라는 것입니다.
코드를 통해 살펴본다면 강좌에 남은 인원을 조회하는 쿼리에 FOR UPDATE 코드를 사용해 락을 걸면 학생 A가 남은 인원을 확인할 때, B는 남은 인원을 확인 못하게 Lock을 할 수 있습니다. B가 남은 인원 조회부터 락이 되어야 하는 이유는 B도 49명으로 조회되면 수강신청 업데이트 로직이 실행될 것이기 때문입니다.

락의 종류에는 공유락과 배타락이 있습니다. 공유락은 데이터를 읽을 때, 배타락은 데이터를 변경할 때 사용되며, 트랜잭션이 완료될 때까지 유지됩니다. 공유락은 공유락끼리 동시에 접근이 가능합니다. 배타락은 락이 해제될 때까지 다른 트랜잭션은 읽기와 쓰기가 허용되지 않습니다. 공유락의 예는 온라인에서 블로그 글읽기이며 배타락의 예는 수강신청입니다. 코드를 통해 보면 공유락은 이름처럼 for share을 붙여주면 되고, 배타락은 for update를 작성해 주면 됩니다.
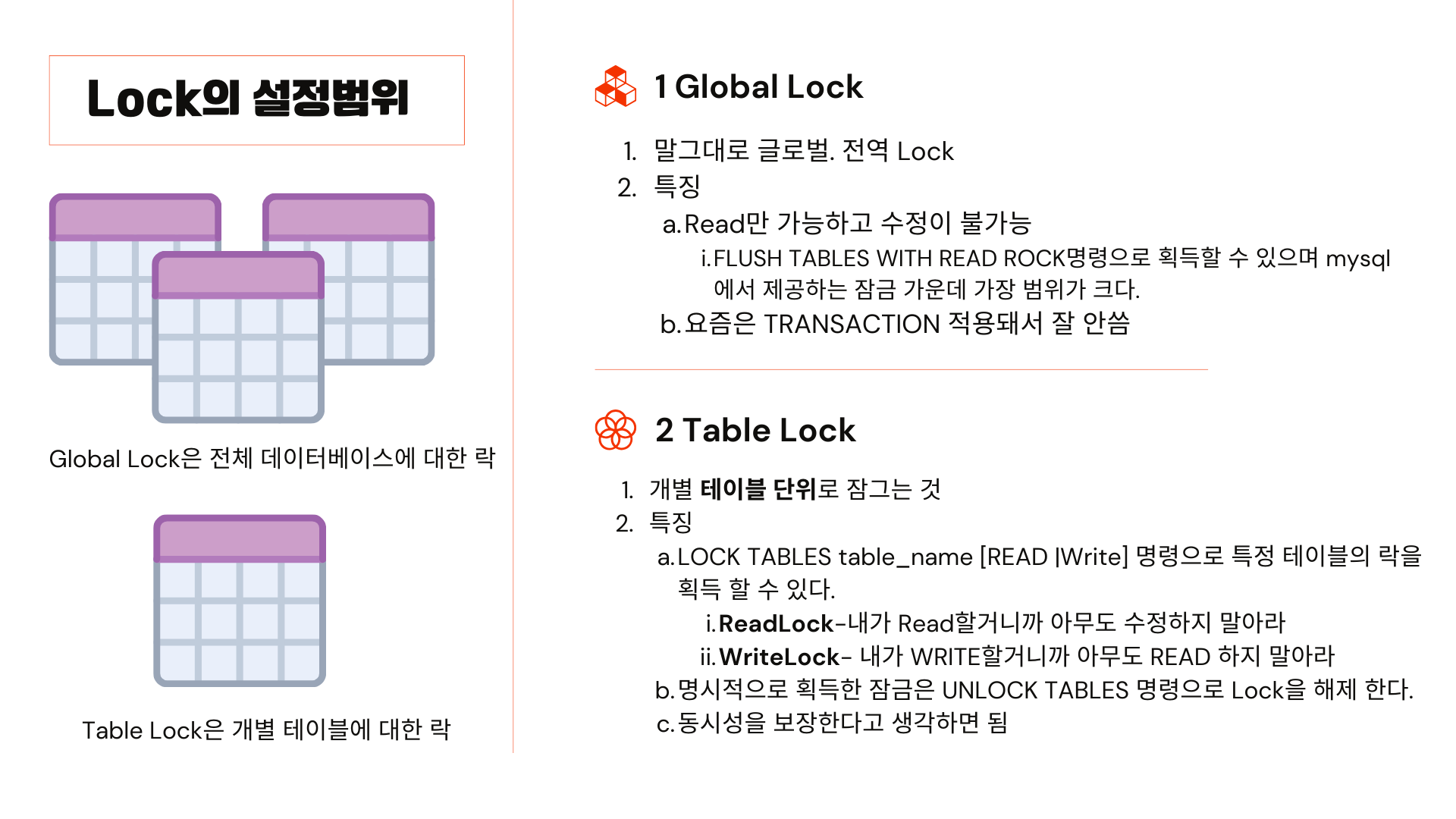
다음은 Lock의 설정범위에 대해 설명하겠습니다. 이 외에도 더 있지만 6개만 설명을 해보자면 첫 번째로 Global Lock이 있습니다. Global Lock은 전체 데이터 베이스에 대한 락이며 Read만 가능하고 수정이 불가능합니다. mysql에서 제공하는 잠금 가운데 가장 범위가 큽니다. 요즘은 잘 사용하지 않는다고 합니다.
두 번째로 Table Lock은 개별 테이블 단위로 잠그는 것이며 Read Lock과 WriteRock이 있습니다. Read Lock은 내가 read 할 거니까 아무도 수정하지 말아라 , WriteLock은 내가 Write 할 거니까 아무도 Read 하지 말아라입니다. 이렇게 하여 동시성을 보장합니다.

우아한 형제들 기술블로그에서 광고시스템은 Named Lock을 활용해 분산락을 구현하고 있었습니다.
글 내용을 정리하자면, 분산 락을 구현할 필요가 있었는데 다른 소프트웨어나 인프라를 사용하면 발생하는 비용과 유지 보수 비용을 생각했고, 이전부터 MySQL을 사용해 왔기에 Named Lock을 이용하면 별다른 비용 없이 분산 락을 구현할 수 있어서 Named Lock을 이용했다고 합니다.
https://velog.io/@this-is-spear/MySQL-Named-Lock

다섯 번째로 레코드락은 스토리지 엔진단에서 락을 잡는 것이며 각 행에 lock을 획득한다고 보면 됩니다. 여섯 번째로 Auto Increment Lock은 여러 클라이언트가 동시에 데이터를 추가하려고 할 때 대비하여 만들어진 락입니다. 예르를 어 id값을 Auto Increment설정해 놨는데 오토 인크리먼트 락이 없다면 동시에 여러 명이 데이터를 추가하면 같은 id를 가진 row들이 여러 개가 될 수 있습니다. 이러한 일을 방지하기 위한 락입니다.
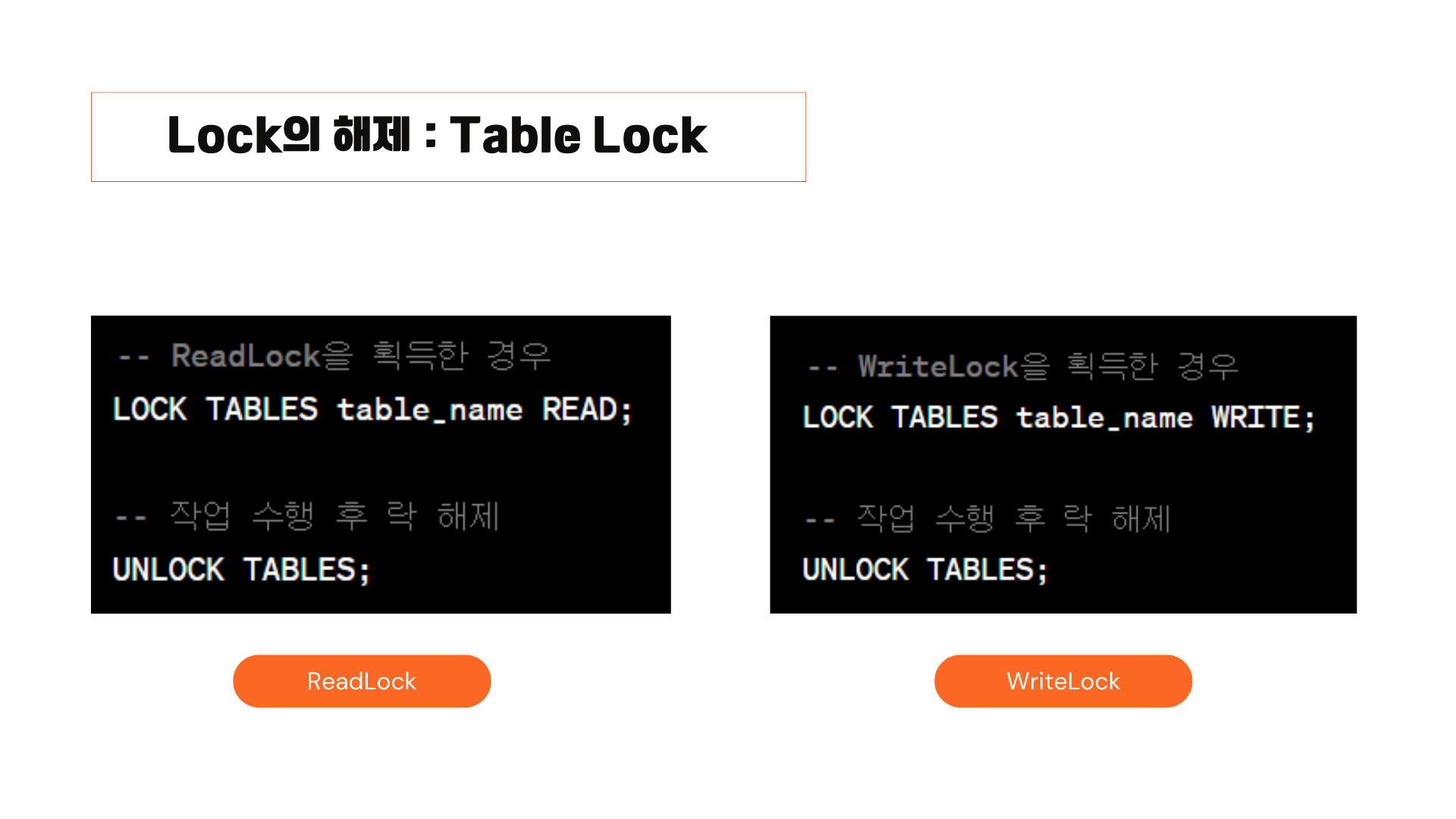
지금까지 락에 대해 알아봤는데 Lock을 해제하려면 어떻게 해야 할까요? 예를 들어 Table Lock은 UNLOCK 테이블명을 작성하여 락을 해제합니다. 락의 종류에 따라 락을 생성하는 방법, 해제하는 방법도 다르니 만약 구글 솔루션 챌린지에서 본인 서비스가 많은 트래픽이나 복잡한 트랜잭션을 고려해야 한다면, 자신의 서비스에 맞게 적절하게 락을 생성하고 해제하여 데이터 무결성을 보장하는 서비스를 만들어보면 좋을 것 같습니다.

감사합니다.
지금까지 1월 교육팀 정기 세션에 대한 내용이었습니다.
다음 포스팅도 기대해 주세요!
출처
[데이터베이스] Lock에 대해서 알아보자 - 기본 편
https://sabarada.tistory.com/m/121
데이터베이스 트랜잭션(transaction)을 아십니까? 그리고 트랜잭션의 매우 중요한 속성들인 ACID를 아십니까? 모르신다면 들렀다 가시지요
'GDSC SungShin Women's University 23-24 > Session' 카테고리의 다른 글
| [3월 정기세션] 비동기와 동시성 & 블록과 논블록(with Python 비동기 프로그래밍 실습 (3) | 2024.05.13 |
|---|---|
| [2월 정기세션] Git merge 문제 해결 (0) | 2024.05.08 |
| [11월 정기세션] Google의 기술 소개와 사용법 (2) | 2024.02.07 |
| [9월 정기세션] GitHub 사용법 교육 (0) | 2023.11.11 |
| [10월 정기세션] 개발 프로젝트 협업툴 교육 (1) | 2023.11.10 |