안녕하세요! GDSC Sungshin Core 멤버 김나은, 송여경 입니다 :)
6월에 진행된 코딩테스트 뿌셔뿌셔 자율스터디 팀의 진행상황에 대해 포스팅하려고 합니다
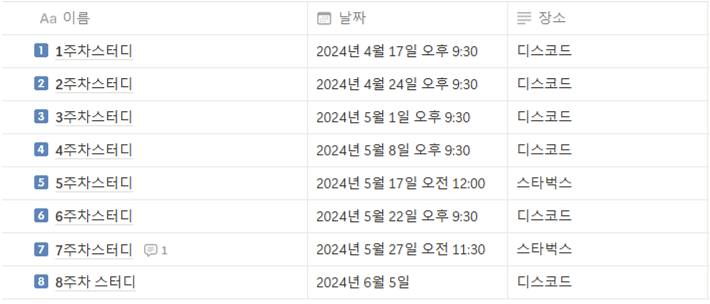
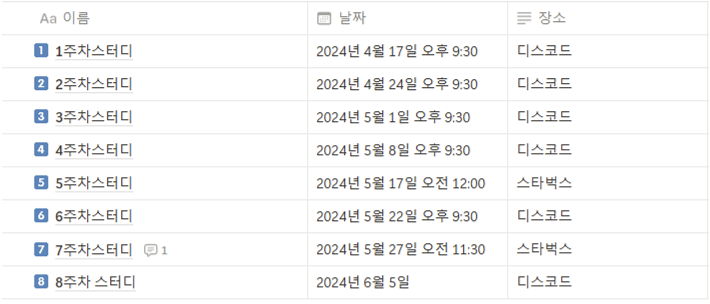
저희는 지난 보고서 이후 2번의 스터디를 진행했습니다!
시험기간을 고려해 진도를 조정하면서 진행하였습니다.
## 정렬
정렬은 알고리즘 중에서도 기본 중에 기본이었는데요!
그 중에서도 가장 재미있었던 정렬 알고리즘 몇가지를 소개해드리겠습니다 : )
### 선택 정렬(Selection Sort)
선택 정렬은 이름에 맞게 현재 위치에 들어갈 값을 찾아 정렬하는 배열입니다.
현재 위치에 저장 될 값의 크기가 작냐, 크냐에 따라 최소 선택 정렬(Min-Selection Sort)와 최대 선택 정렬(Max-Selection Sort)로 구분 할 수 있습니다.
그렇다면, 최소 선택 정렬은 오름차순으로 정렬될 것이고, 최대 선택 정렬은 내림차순으로 정렬될 것입니다.
기본 로직은 다음과 같습니다.
- 정렬 되지 않은 인덱스의 맨 앞에서 부터, 이를 포함한 그 이후의 배열값 중 가장 작은 값을 찾아간다.
(정렬되지 않은 인덱스의 맨 앞은, 초기 입력에서는 배열의 시작위치일 것!)
1. 가장 작은 값을 찾으면, 그 값을 현재 인덱스의 값과 바꿔준다.
2. 다음 인덱스에서 위 과정을 반복해준다.
이 정렬 알고리즘은 7-1개,n-2개,.,1개씩 비교를 반복한다.
그렇다면, 가장 중요한 시간 복잡도는 0(n^2)이 되겠죠!
공간 복잡도는 단 하나의 배열에서만 진행하기 때문에 0(n)이 됩니다.
### 삽입 정렬(Insertion Sort)
삽입 정렬은 현재 위치에서, 그 이하의 배열들을 비교하여 자신이 들어갈 위치를 찾아, 그 위치에 삽입하는 배열 알고리즘입니다.
기본 로직을 소개하겠습니다.
1. 삽입 정렬은 두 번째 인덱스부터 시작한다. 현재 인덱스는 별도의 변수에 저장해주고, 비교 인덱스를 현재 인덱스 1로 잡는다.
2. 별도로 저장해 둔 삽입을 위한 변수와, 비교 인덱스의 배열 값을 비교한다.
3. 삽입 변수의 값이 더 작으면 현재 인덱스로 비교 인덱스의 값을 저장해주고, 비교 인덱스를 1하여 비교를 반복한다.
4. 만약 삽입 변수가 더 크면, 비교 인덱스+1에 삽입 변수를 저장한다.
이 정렬 알고리즘 또한 최악의 경우(역으로 정렬되어있을 경우) n-1개,n-2개,•,1개씩 비교를 반복하여 시간복잡도는 0(n^2)이지만,
이미 정렬되어 있는 경우에는 한번씩 밖에 비교를 하지 않아 시간 복잡도는 0(n)이 됩니다!!
하지만 상한을 기준으로 하는 Big-O notation은 최악의 경우를 기준으로 평가하므로 삽입 정렬의 시간복잡도는 0(n^2)입니다.
공간복잡도는 단 하나의 배열에서만 진행하므로 0(n)이 됩니다.
여기까지가 대표적인 정렬 알고리즘 두개였는데요!
이 외에도, 버블 정렬, 합병 정렬, 퀵 정렬 등등을 의논하는 시간도 가졌습니다.
이를 바탕으로 푼 문제는 두가지 였습니다.
### 위에서 아래로
문제
하나의 수열에는 다양한 수가 존재한다. 이러한 수는 크기에 상관없이 나열되어 있다. 이 수를 큰 수부터 작은 수의 순서로 정렬해야 한다. 수열을 내림차순으로 정렬하는 프로그램을 만드시오.
> 입력
>
>
> 첫째 줄에 수열에 속해 있는 수의 개수 N이 주어진다.(1<=n<=500)
>
> 둘째 줄부터 N+1번째 줄까지 N개의 수가 입력된다. 수의 범위는 1이상 100,000이하의 자연수이다.
>
> 출력
입력으로 주어진 수열이 내림차순으로 정렬된 결과를 공백으로 구분하여 출력한다. 동일한 수의 순서는 자유롭게 출력해도 괜찮다
>
가장 효율적인 코드
```swift
n = int(input())
array = []
for i in range(n):
array.append(int(input()))
array = sorted(array, reverse=True)
for i in array:
print(i, end=' ')
```
sort를 이용해서 풀 수 있는 아주 간단한 문제였습니다.

```swift
n = int(input())
array = []
for i in range(n):
data = input().split()
array.append((data[0], int(data[1])))
array = sorted(array, key=lambda x:x[1])
for x in array:
print(x[0], end=' ')
```
처음에 학생:점수 이걸 보고 dict을 사용해서 풀려고 시도하였지만,
이 문제는 계수 정렬을 이용해서 푸는 문제로 소개가 되어있는데 튜플 형태로 푸는 것이 효과적이었습니다.
key값(x[1])을 이용하여 점수를 기준으로 정렬을 하고 x[0]을 출력하게 하면 해결할 수 있었습니다.
## 이진 탐색
이진 탐색은 순차 탐색과 달리 배열 내부의 데이터가 정렬되어 있어야만 사용할 수 있는 알고리즘입니다.
데이터가 무작위일 때는 사용할 수 없지만, 정렬되어 있다면 매우 빠르게 탐색이 가능하다는 장점이 있습니다.
이진 탐색을 공부하면서 풀어본 문제는 백준 1920번 ‘수 찾기’ 문제입니다.
이진 탐색에 대해 공부하며 본 소스 코드들을 활용해 문제를 해결하였습니다.
여러 소스 코드들이 있는 만큼 팀원들마다 사용한 소스 코드와 그것을 활용한 코드가 다양했습니다.
팀원들과 개념 공부와 함께 코드들을 하나씩 리뷰하며 열심히 스터디를 진행했습니다. 🙂

그 결과 저희 스터디가 CLC 러닝스터디 우수 스터디가 선정되었습니다!! (짝짝)
스터디 팀원 모두 끝까지 성실하고 열심히 공부하였기 때문에 이런 결과를 받을 수 있었던 것 같습니다!
이상으로 저희 코딩스터디 뿌셔뿌셔 자율 스터디를 성공적으로 마쳤습니다!
감사합니다😊
'GDSC SungShin Women's University 23-24 > Study' 카테고리의 다른 글
| [자율스터디] 코딩테스트 Team 2 6월 보고서 (0) | 2024.08.17 |
|---|---|
| [자율스터디] Node.js와 Github 스터디 팀 6월 보고서 (0) | 2024.08.17 |
| [자율스터디] 아파치 카프카 스터디 팀 5월 보고서 (0) | 2024.08.05 |
| [자율스터디] 코테스터디 Team4 5월 보고서 (0) | 2024.07.19 |
| [자율스터디] 알고리즘 스터디 5월 보고서 (0) | 2024.07.19 |