
안녕하세요! GDSC Sungshin 교육팀 김도은입니다 :)
2024년 4월 정기세션에서 교육팀은 '실무에서 자주사용하는 툴인 ELK,메세지큐에대한 간단한 소개와 필요성'이라는 주제로 교육을 진행했습니다.
목차는 다음과 같습니다.
여러분은 프로젝트 또는 과제를 하면서 에러가나면
로그를 보고 찾아본적이 있나요?
학부생과제수준으로는 에러가나는곳을찾기위해
Print문 또는 디버거를 사용할거같은데요?
로깅라이브러리를 이용해서 프린트문을 다 로깅함수로바꿔서 파일에 로그를 남겨둘수도 있습니다.
특히 운영하고 있는 시스템에 장애가 발생하면
발빠르게 대응하기 위해 로그를보고 분석해서 대응해야합니다.
그래서 로그는 완성된 시스템을 안정적으로 운영하기 위해서 필수적입니다!
이 로그를 수집, 처리, 분석하는 기술이 ELK 스택입니다.
ELK스택은 엘라스틱서치, 로그스태시, 키바나의 약어입니다.
* 로그: 분석이 필요한 서버 로그를 식별합니다.
* Logstash: 로그 및 이벤트 데이터를 수집합니다. 데이터를 구문 분석하고 변환하기도 합니다.
* ElasticSearch: Logstash에서 변환된 데이터는 저장, 검색 및 인덱싱됩니다.
* Kibana: Kibana는 Elasticsearch DB를 사용하여 탐색, 시각화 및 공유합니다.
* 여기서 매우 많은 양의 데이터를 처리하는 동안 버퍼링 및 복원력을 위해 Kafka, RabbitMQ가 필요할 수 있습니다.보안을 위해 nginx를 사용할 수 있습니다.
* Kafka, RabbitMQ의 필요성은 로그의 유실을 최대한 방지하기 위함이고, 현재 구축하고자 하는 시 스템의 로그가 중요한 부분이라면 네트워크 등에 의한 이슈가 발생하지 않도록 이렇게 설계할 수 있습니다.
* 만약 로그 의 유실을 용인할 수 있는 상황이라면 굳이 카프카까지 넣을 필요는 없습니다. 불필요하게 카 프카 운영 비용이 증가할 수 있으므로, 해당 부분은 시스템 상황에 맞게 가져가는 것이 좋습니다.
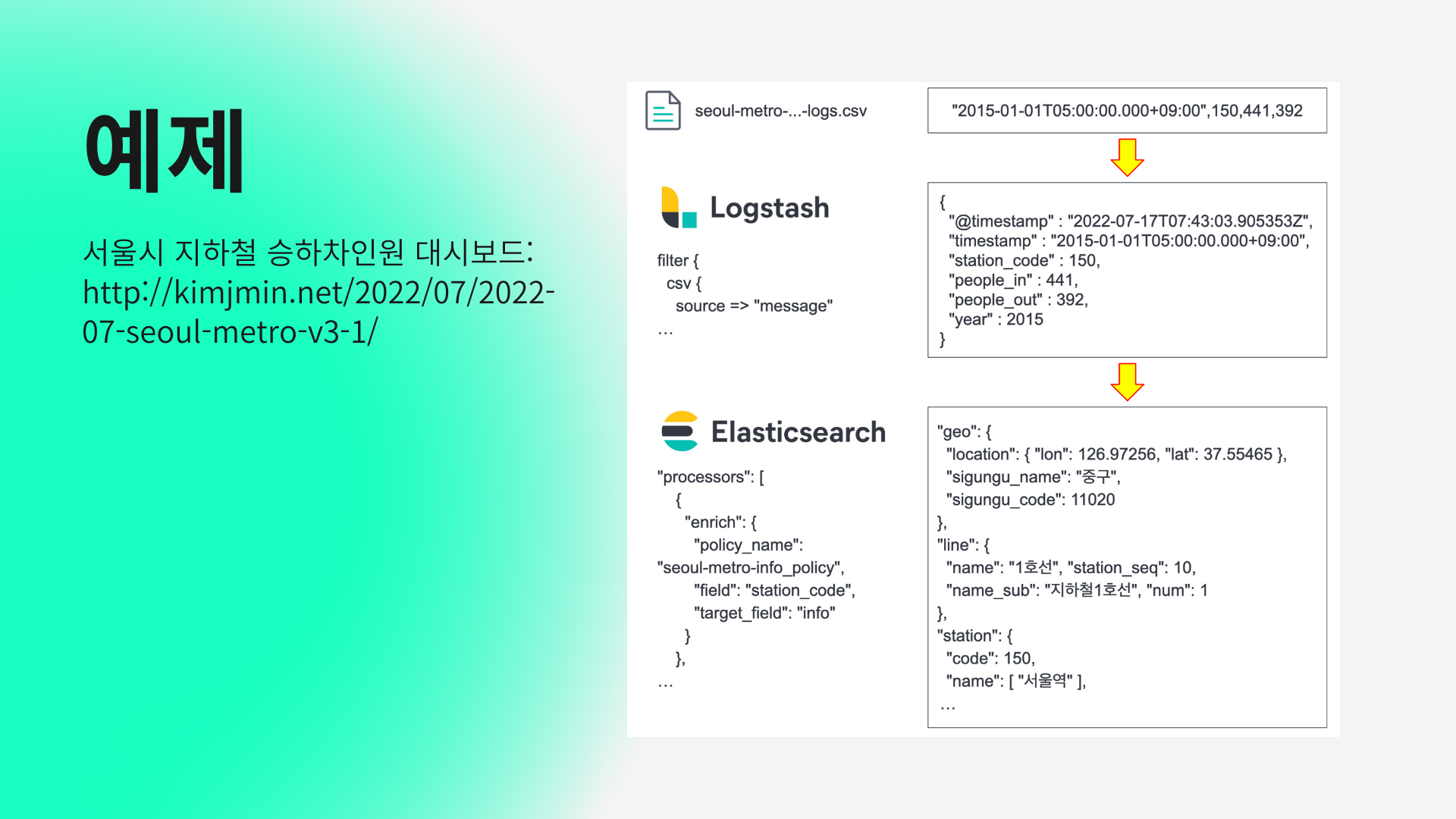
예제를보자면
Logstash 로 csv파일에서 데이터를 수집해서 csv 형식을 파싱하고 elasticsearch 로 내보내서 우리가 원하는 데이터로 검색해서 볼수있습니다.
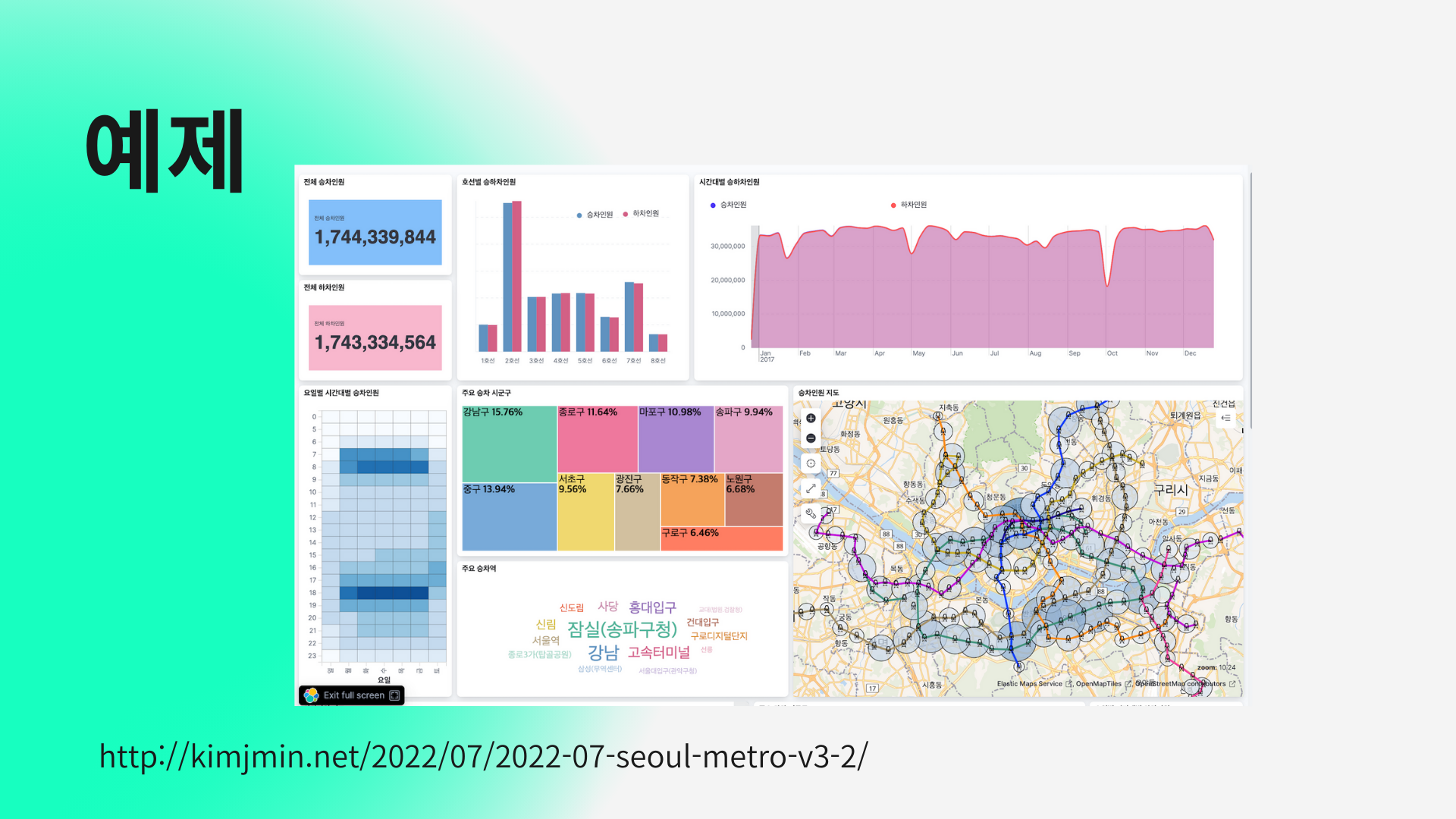
그후 키바나를이용해 이렇게 시각화해서 보여줄수 있습니다.

다음으로 메세지 지향 미들웨어 소개입니다.
많이 쓰이는 래빗엠큐와 카프카에 대해 소개를 하기에 앞서 이것들을 소개하기 위해서는 메시지 지향미들웨어라는 개념소개부터 필요하다고 판단이 되어서 이 메시지지향미들웨어소개부터 시작하겠습니다.
mom은 쉽게 말해 응용소프트웨어 간의 비동기적 데이터 통신을 위한 소프트웨어입니다.즉, 비동기적(Asynchronous) 방식을 이용해서 프로세스간의 데이터를 주고 받는 기능을 위한 시스템입니다.
메세지 지향 미들웨어는 메세지를 전달하는 과정에서 보관하거나 라우팅 및 변환할 수 있다는 장점을 가집니다.
제가 핵심적으로 다룰 메세지 큐 는 메세지 지향 미들웨어에 속합니다.

먼저 메시지 큐에 대해서 알아보기전 큐에 대해서 설명드리면 Queue 란 선입선출(First in First out) 구조를 가진 자료구조입니다.
Queue 는 2개의 끝을 가지며 각각은 입구와 출구입니다. 새로운 데이터는 입구로 들어오고 나가는 데이터는 출구에서 나갑니다.메세지 큐(Message Queue) 란 Queue 라는 자료구조를 채택해서 메세지를 전달하는 시스템이며, 메세지 지향 미들웨어(MOM) 을 구현한 시스템입니다.
메세지 큐를 통해 메세지를 전달하려면 메세지를 전달하는 부분과 메세지를 받는 부분이 필요하겠죠?
여기서 메세지를 발행하고 전달하는 부분을 Producer 라고 하며, 메세지를 받아서 소비하는 부분을 Consumer 라고 합니다.
메세지 큐는 Producer 와 Consumer 의 메세지 전달 역할을 하는 매개체입니다.
메세지 큐는 요즘 가장 핫한 소프트웨어 아키텍처 디자인 패턴인 MSA(Microservice Architecture) 에서 아키텍처의 핵심적인 역할을 합니다


그렇다면 메시지 큐를 왜쓸까요?
정보의 전달방법으로 API 통신, Socket 통신 같은 방식에 익숙하고
메시지 큐를 퉁한 데이터 교환은 익숙하지 않습니다.
메시지큐는 거대한 양의 데이터를 분산해서 처리해야할 때사용됩니다.
모니터링, 로그, 정산 등의 큰 작업에서 Queue는 여러 컴포넌트들이 데이터를 생성하고 저장할 때 버퍼 역할을 수행하게 됩니다.
Producer와 Consumer의 속도가 차이가 있을때 장애가 나더라도 Queue가 버퍼
역할을 수행해주기 때문에 장애가 전파되는 일을 방지할 수 있습니다.

메세지브로커 vs 이벤트브로커
메세지 큐에서데이터를 운반하는 방식에 따라 메세지 브로커와 이벤트 브로커로 나눌 수 있습니다.
- 메세지 브로커는 Producer 가 생산한 메세지를 메세지 큐에 저장하고, 저장된 메세지를 Consumer가 가져갈 수 있도록 합니다.
- 메세지 브로커는 Consumer 가 메세지 큐에서 데이터를 가져가게 되면 짧은 시간 내에 메세지 큐에서 삭제되는 특징이 있습니다
ex)RabbitMQ, ActiveMQ, AWS SQS, Redis
- 이벤트 브로커또한 기본적으로 메세지 브로커의 역할을 할 수 있습니다. 하지만 메세지 브로커는 이벤트 브로커의 기능을 하지 못합니다.
- 이벤트 브로커가 관리하는 데이터를 이벤트라고 하며 Consumer 가 메세지 큐에서 데이터를 가져가게 되면 짧은 시간 내에 메세지가 삭제되는 것과 달리, 이벤트 브로커 방식에서는 Consumer 가 소비한 데이터를 필요한 경우 다시 소비할 수 있습니다.
- 또한 메세지 브로커 보다 대용량 데이터를 처리할 수 있는 능력이 있습니다.
ex)Kafka
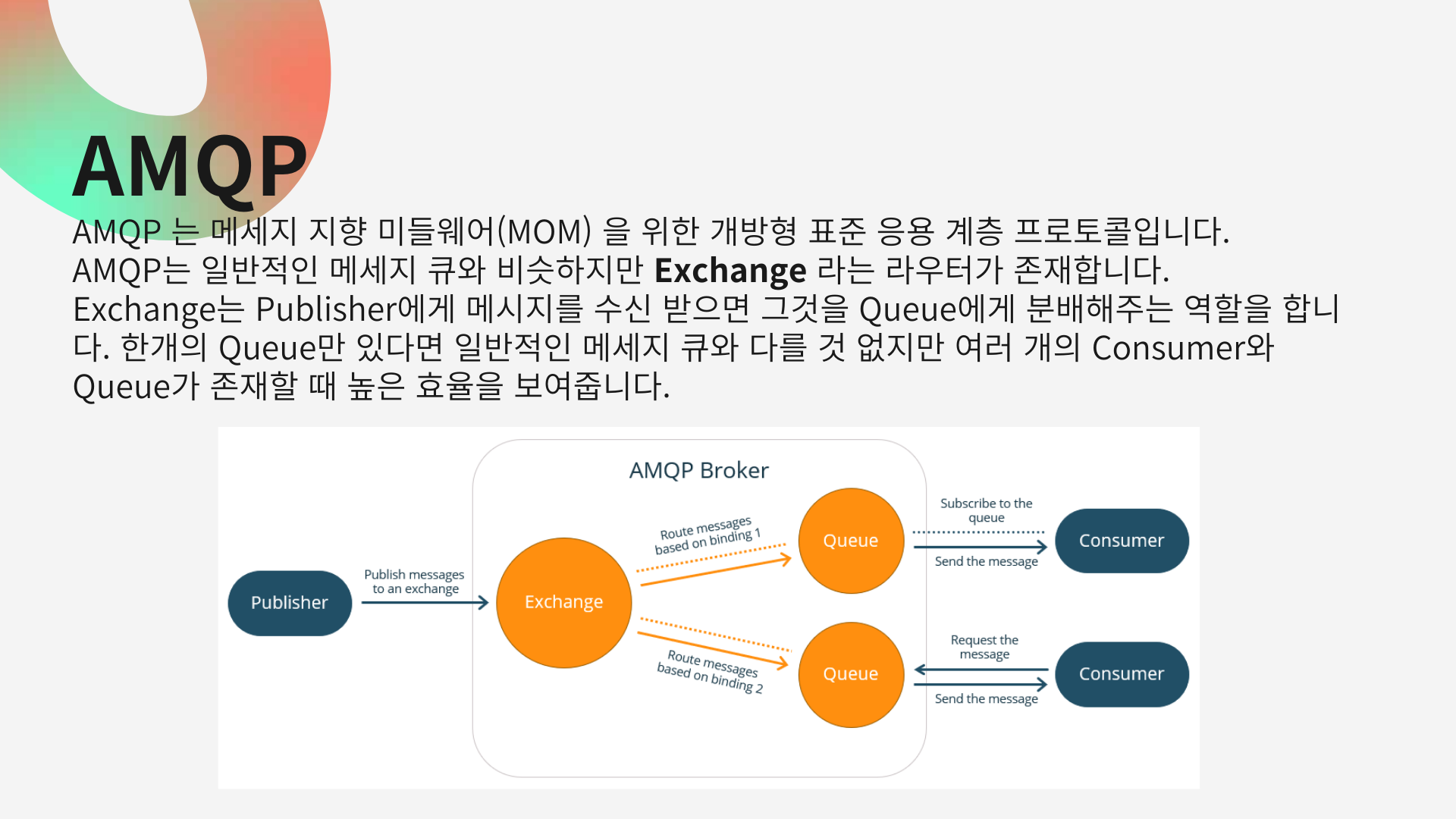
래빗엠큐에 대해 알아보기전 amqp라는 개념에 대해 알아야합니다.
AMQP 는 메세지 지향 미들웨어(MOM) 을 위한 개방형 표준 응용 계층 프로토콜입니다.
AMQP는 일반적인 메세지 큐와 비슷하지만Exchange(그림가리키며)라는 라우터가 존재합니다.
Exchange는 Publisher에게 메시지를 수신 받으면 그것을 Queue에게 분배해주는 역할을 합니다. 한개의 Queue만 있다면 일반적인 메세지 큐와 다를 것 없지만 여러 개의 Consumer와 Queue가 존재할 때 높은 효율을 보여줍니다.

다음으로 레빗엠큐에 대해 알아보겠습니다.
RabbitMQ 는 방금 알아본 AMQP프로토콜을 구현해 놓은 오픈 소스 메시지 브로커이며 여러가지 특성을 가집니다.
-AMQP 을 구현해 놓은 메세지 큐입니다.
-신뢰성,안전성과 성능을 충족할 수 있도록 다양한 기능을 제공합니다.
-유연하고 복잡한 라우팅이 가능합니다.
-관리 UI가 존재합니다.
-거의 모든 언어와 운영체제를 지원합니다.
-데이터 처리 보단, 관리적 측면이나 다양한 기능 구현을 위한 서비스를 구축할 때 사용합니다.
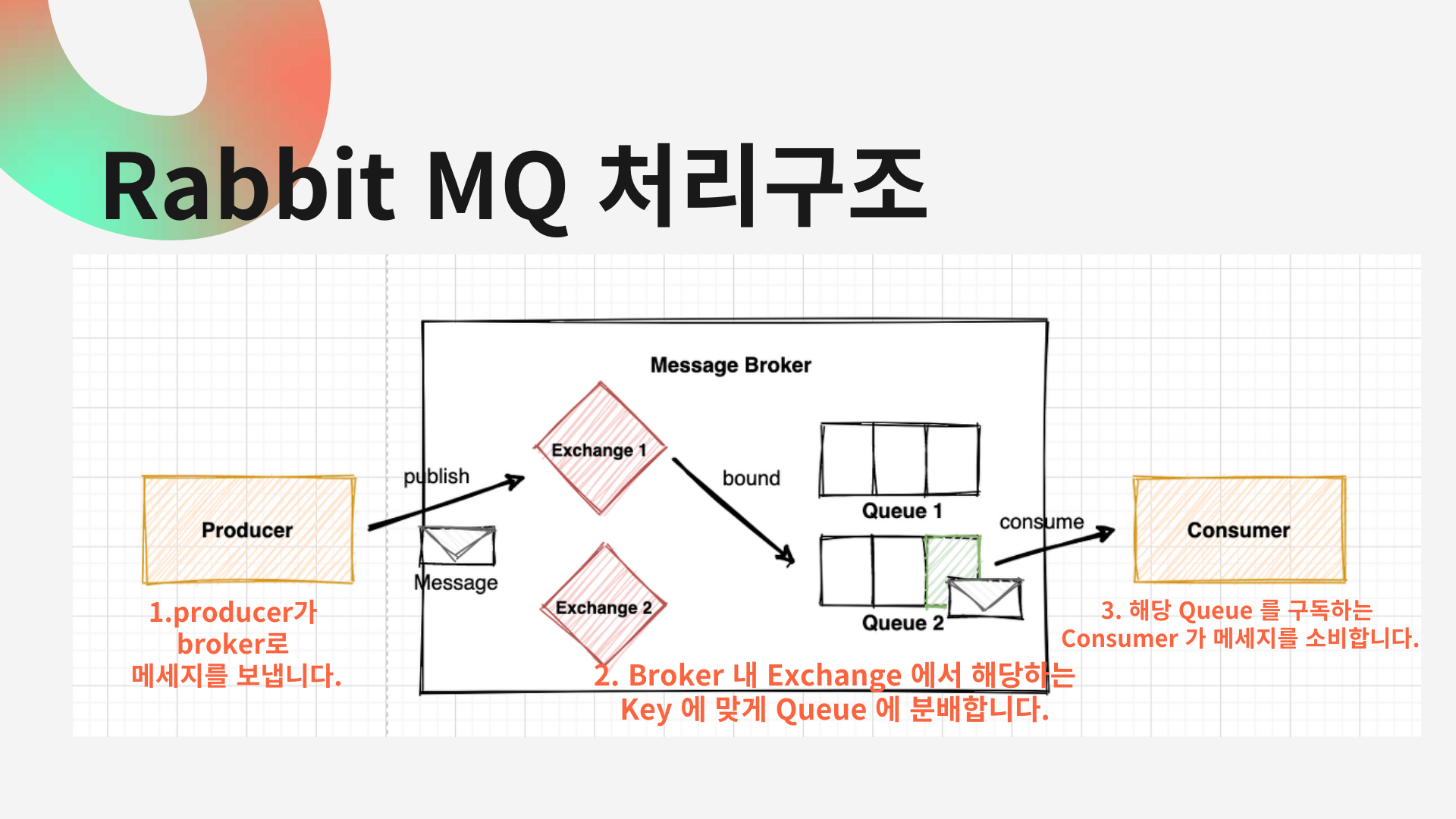
다음으로 레빗엠큐 처리구조입니다.
먼저 1.producer가 broker로 메세지를 보냅니다. 2. Broker 내 Exchange 에서 해당하는 Key 에 맞게 Queue 에 분배합니다.
3. 해당 Queue 를 구독하는 Consumer 가 메세지를 소비합니다.

다음으로 아까 이벤트브로커때 잠시 나온 카프카에 대해 알아보겠습니다. 현재 가장 많이 사용되는 MOM(Message Oriented Middleware)입니다.
Apache 재단에서 관리하는 Kafka 는 고성능 데이터 파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 application을 위한 오픈 소스 분산 이벤트 스트리밍 플렛폼입니다.

특징으로는 첫번째는 카프카는 지향하는 바가 다른 메시지 큐와 다릅니다. 실시간 데이터 피드를 관리하기 위해 통일된 높은 throughput의 낮은 latency 를 지닌 플랫폼을 제공하는것이 목표입니다.
두번째는 pub-sub 구조를 가집니다.
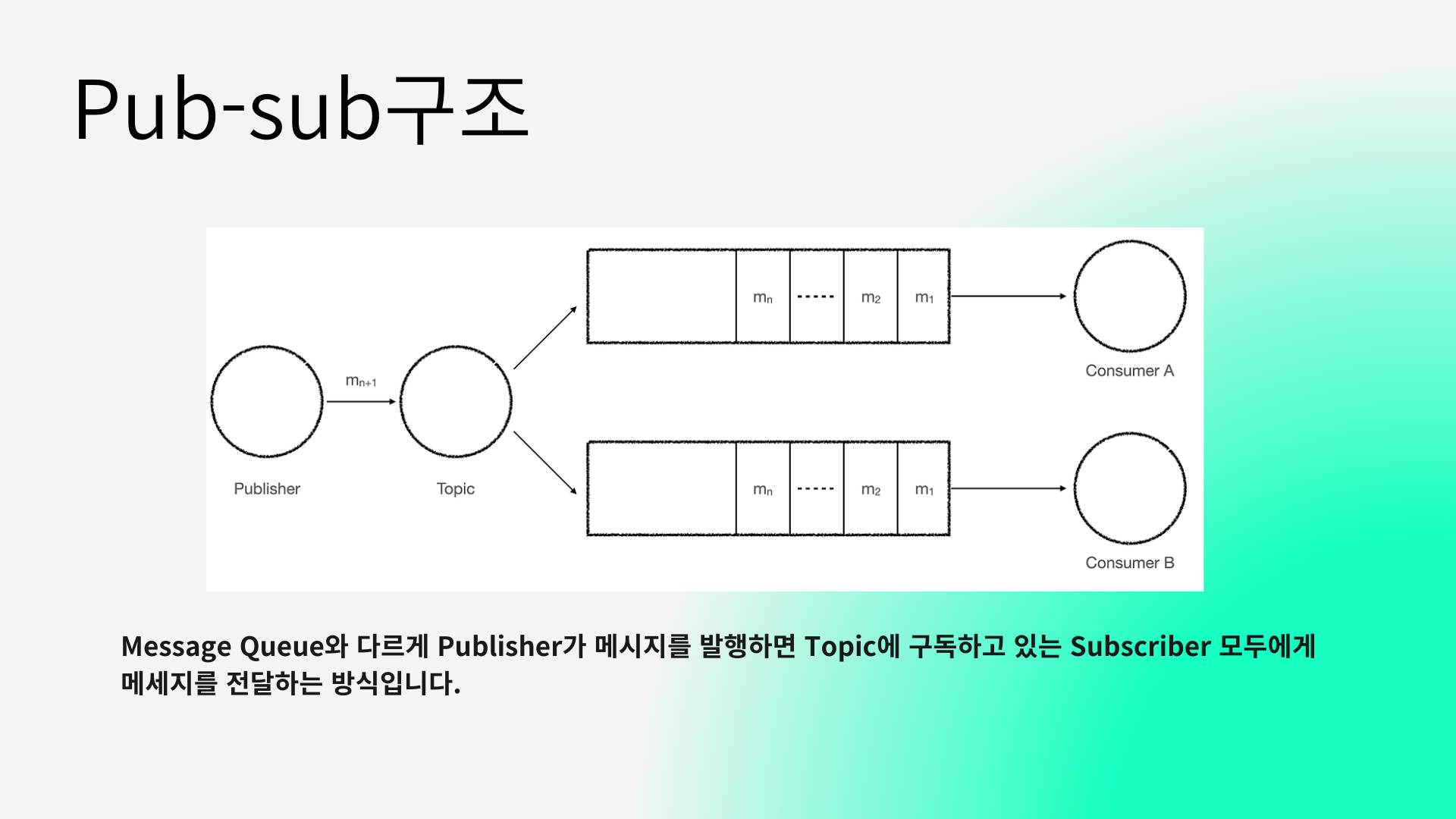
여기서 pubsub(펍섭) 구조란 Message Queue와 다르게 Publisher가 메시지를 발행하면 Topic에 구독하고 있는 Subscriber 모두에게 메세지를 전달하는 방식입니다.

특성 세 번째는 디스크에 메시지를 저장합니다. 다른 메세지큐와의 가장 큰 차이점은 통신할때 TCP/IP통신을 통해 바로 디스크로 쓴다는 점입니다. 카프카는 별도의 설정 없이 디스크에 적재하며, 환경설정에서 그 주기를 변경 할 수 있습니다.
다음으로는 분산 환경에 특화되도록 설계되었습니다. 하나의 카프카 클러스터는 3대의 브로커로 부터 시작해 수십대의 브로커로 확장 가능합니다.
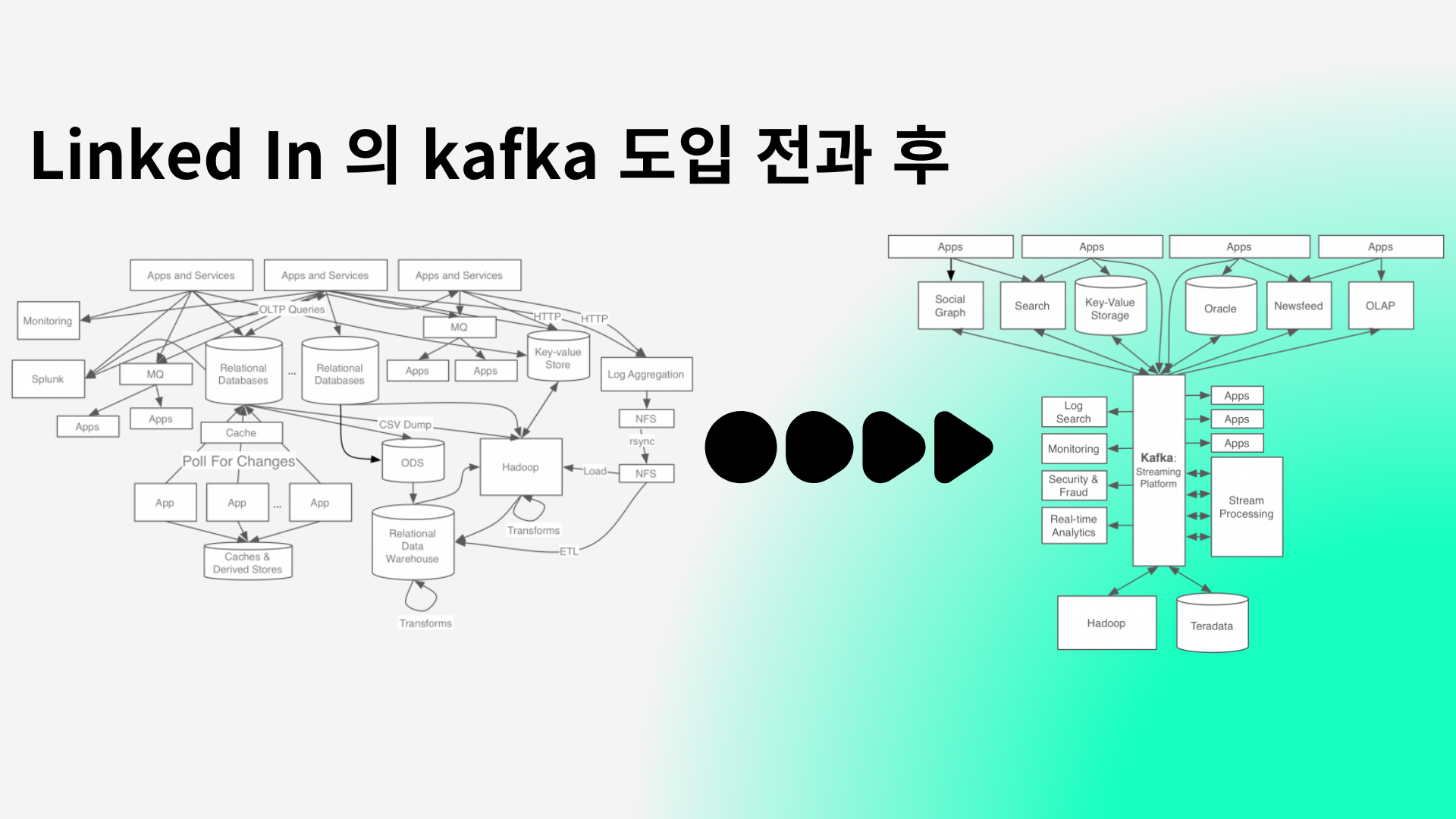
Kafka 는 현재 아파치 재단에서 관리되고 있지만 linked in 에서 만들어졌습니다. 카프카 도입 후를 보면 모든 이벤트와 데이터의 흐름이ᅠ카프카를 중심으로 모이고 퍼지는 것을 알 수 있습니다.이렇듯 카프카는 전통적인 메시지 큐 시스템인 RabbitMQ와 같은 메시징 시스템과 비교할 때 처리량과 처리 속도, 가용성과 확장성이 월등히 앞서는 것을 알 수 있습니다.
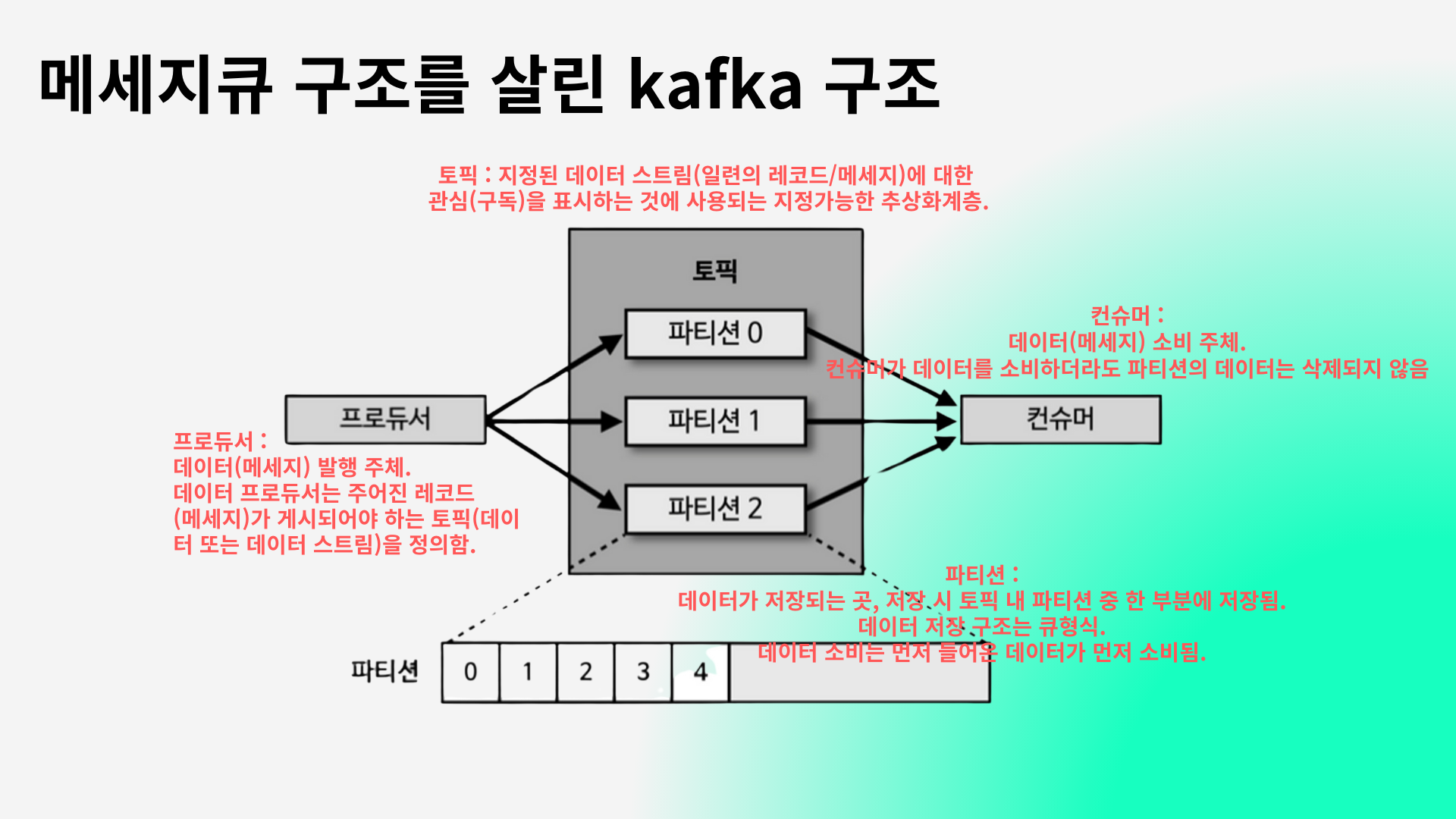
마지막으로 카프카의 구조에 대해 알아보고 마무리하겠습니다.
간단히 말해 프로듀서에서 토픽을 거쳐 컨슈머로 가는형태인데 프로듀서는 데이터(메세지) 발행 주체이고, 토픽은 지정된 데이터 스트림(일련의 레코드/메세지)에 대한 관심(구독)을 표시하는 것에 사용되는 지정가능한 추상화계층입니다.
파티션은 데이터가 저장되는 곳입니다 데이터 저장 구조는 큐형식.
다음으로 컨슈머는 데이터(메세지) 소비 주체입니다. 컨슈머가 데이터를 소비하더라도 파티션의 데이터는 삭제되지 않습니다.

정리하자면 대용량 분산 시스템이 필요하면 Kafka 을 구축하면 되고 그 외에는 Queue 기능에서 신뢰성과 안전성을 좀 더 보장하는 RabbitMQ 을 사용하면 될 것 같습니다. 현재 메세지 큐는 MSA 와 가장많이 사용되는 시스템입니다.
따라서 대표적인 메세지큐에 대한 개념을 꼭 정리하고 실제로 서버에 구축해보는 경험이 필수적이라고 생각합니다.
'GDSC SungShin Women's University 23-24 > Session' 카테고리의 다른 글
| [5월 정기세션] GPT-4o& Google Astra project (0) | 2024.06.24 |
|---|---|
| [3월 정기세션] 비동기와 동시성 & 블록과 논블록(with Python 비동기 프로그래밍 실습 (3) | 2024.05.13 |
| [2월 정기세션] Git merge 문제 해결 (0) | 2024.05.08 |
| [1월 정기세션] Database (2) | 2024.02.10 |
| [11월 정기세션] Google의 기술 소개와 사용법 (2) | 2024.02.07 |